Appearance
控制平面监控
Kubernetes 控制平面负责保存集群状态、处理 API 请求、调度 Pod、维护控制器循环和服务发现。控制平面异常时,已经运行的业务 Pod 可能还在工作,但新发布、扩缩容、配置下发、服务发现和事件写入都会受到影响。
K3s 的控制平面和 kubeadm 集群不完全一样。API Server 仍然是集群入口,CoreDNS 仍然负责集群内域名解析;Scheduler、Controller Manager 在 K3s server 进程里,默认暴露和采集方式需要单独处理。
一、Prometheus Target
控制平面监控先看 Prometheus 是否采到了目标。up=1 只能说明 Prometheus 能抓到 /metrics,具体是否慢、是否报错,还要继续查业务指标。
操作路径:
Status -> Target health (中文:状态 -> 目标健康)
操作步骤:
- 进入
Status -> Target health。 - 在搜索框输入
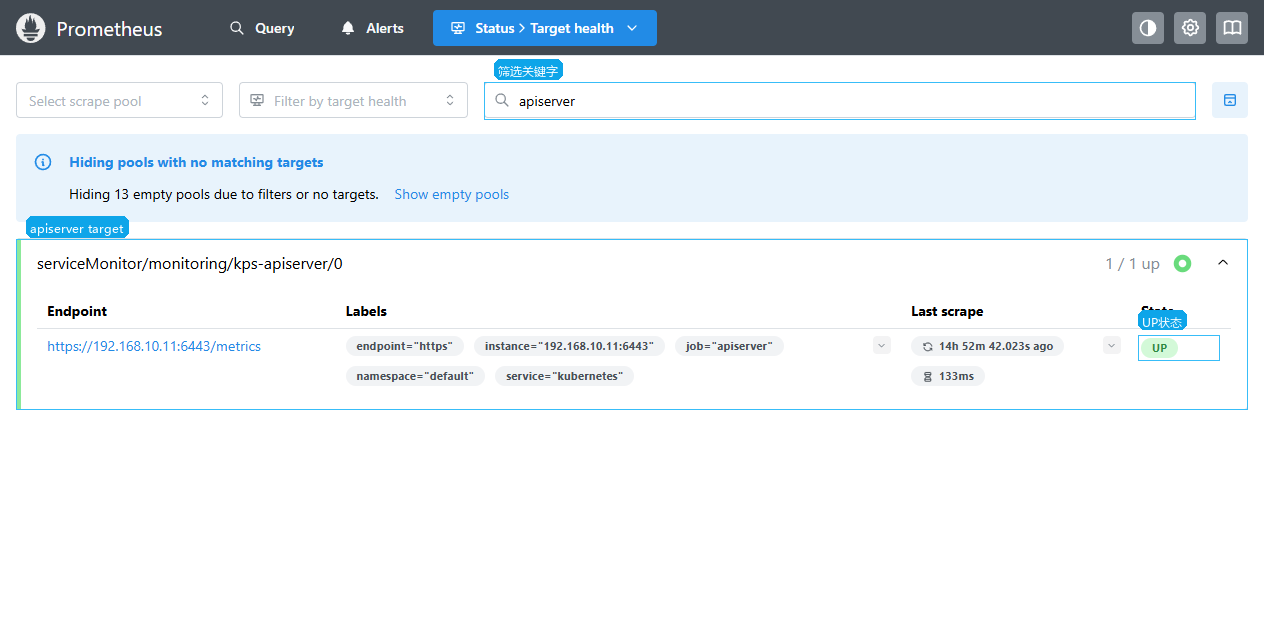
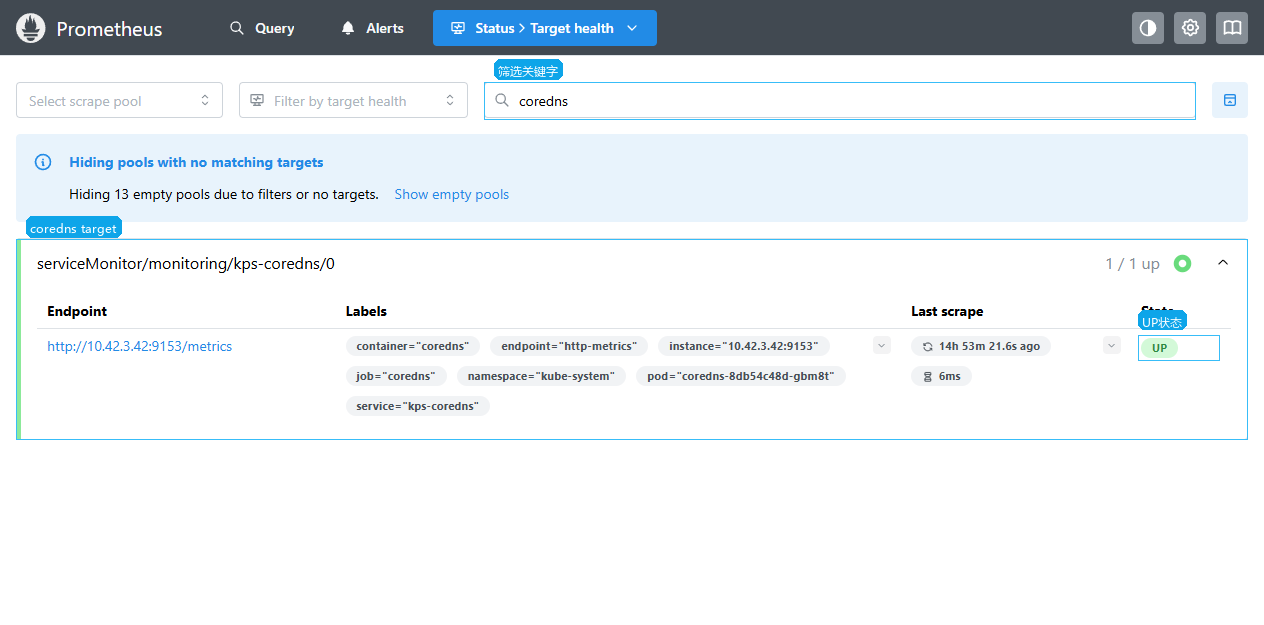
apiserver或coredns。 - 查看对应 target 的
State、Last scrape和展开后的Last error。
查看 API Server target:
查看 CoreDNS target:
Target 常见字段:
| 字段 | 含义 |
|---|---|
Endpoint | Prometheus 实际抓取的地址 |
Labels | 这条 target 带上的标签,PromQL 聚合会用到 |
Last scrape | 最近一次抓取时间和耗时 |
State | UP 表示抓取成功,DOWN 表示抓取失败 |
如果 target 是 DOWN,排查入口通常是 ServiceMonitor、Service、Endpoints 和证书。API Server 使用 HTTPS,证书和权限错误也会表现为抓取失败。
二、API Server
API Server 是 Kubernetes 的 HTTP API 入口。kubectl、kubelet、controller、scheduler、Operator 都会访问它。发布系统突然变慢、kubectl get pod 卡顿、Operator 一直重试时,API Server 的请求量、错误码和延迟是主要入口。
操作路径:
Query -> Table (中文:查询 -> 表格)
操作步骤:
- 进入 Prometheus
Query。 - 选择
Table。 - 输入 PromQL。
- 点击
Execute。
API Server 请求按动作、资源和状态码拆开:
promql
sum by (verb, resource, code) (
rate(apiserver_request_total[2m])
)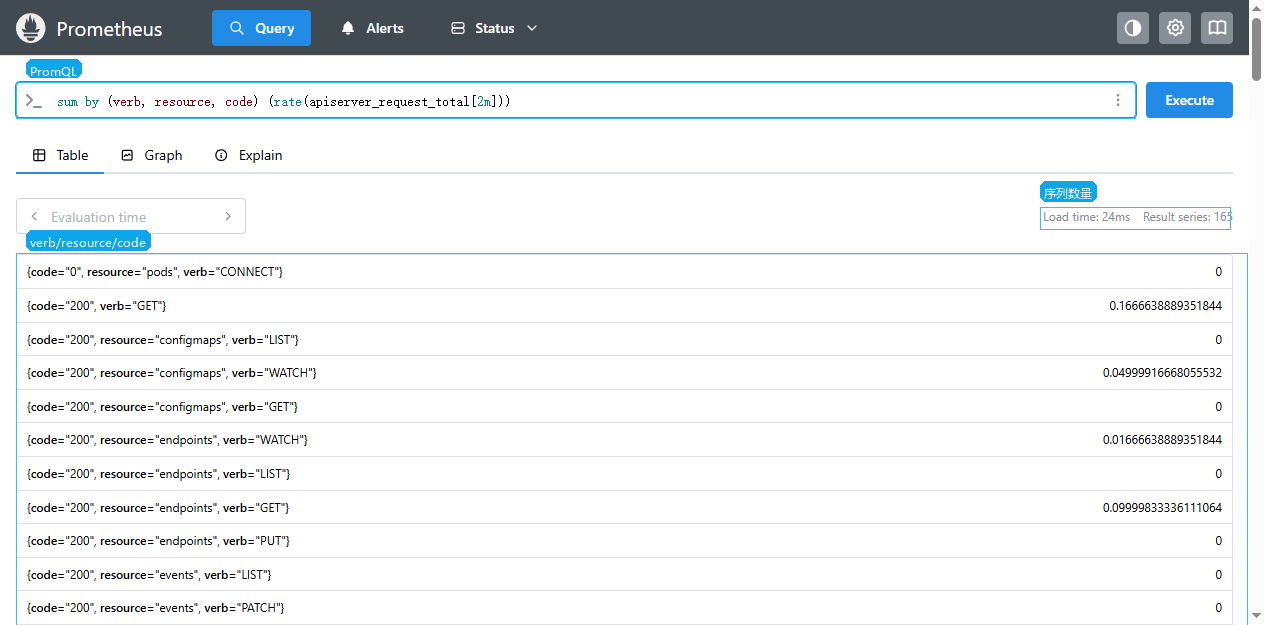
verb 表示动作,比如 GET、LIST、WATCH、POST、PUT、PATCH。resource 表示访问的对象,比如 pods、nodes、configmaps。code 是 HTTP 状态码。排查时先看是否有大量 5xx,再看是哪个资源和动作集中异常。
常用查询:
promql
# API Server 每秒请求量,按动作、资源、状态码拆分
sum by (verb, resource, code) (
rate(apiserver_request_total[5m])
)
# API Server 5xx 错误,适合看服务端异常
sum by (verb, resource) (
rate(apiserver_request_total{code=~"5.."}[5m])
)
# API Server P99 延迟,按动作和资源拆开
histogram_quantile(
0.99,
sum by (le, verb, resource) (
rate(apiserver_request_duration_seconds_bucket[5m])
)
)API Server 延迟高时,常见方向有 etcd 慢、API 请求量突增、某个 controller 大量 list/watch、Webhook 变慢。K3s 默认使用 SQLite、外部数据库或嵌入式 etcd 的方式不同,排查时要按实际数据存储后端确认指标来源。
三、CoreDNS
CoreDNS 负责集群内服务发现。Pod 通过 svc.namespace.svc.cluster.local 或短域名访问 Service 时,最终会走 CoreDNS。DNS 异常时,应用表现常见为连接数据库失败、服务间调用偶发超时、启动阶段解析域名失败。
CoreDNS 响应码可以快速判断解析结果:
promql
sum by (rcode) (
coredns_dns_responses_total
)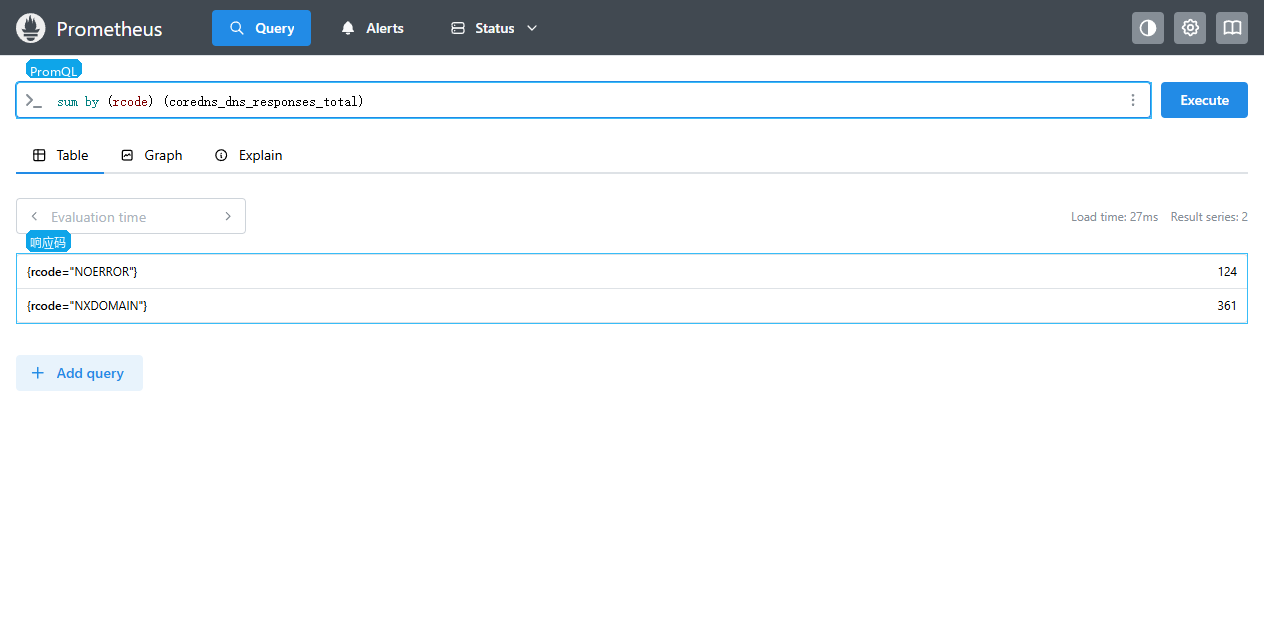
常见响应码:
| 响应码 | 含义 |
|---|---|
NOERROR | 解析成功 |
NXDOMAIN | 域名不存在,常见于写错 Service 名或 namespace |
SERVFAIL | 服务端解析失败,常见于上游 DNS 或 CoreDNS 插件异常 |
REFUSED | 查询被拒绝 |
CoreDNS 常用查询:
promql
# DNS 请求量,按查询类型拆开
sum by (type) (
rate(coredns_dns_requests_total[5m])
)
# DNS 响应码,适合看 NXDOMAIN / SERVFAIL 是否异常增长
sum by (rcode) (
rate(coredns_dns_responses_total[5m])
)
# DNS 请求耗时 P99
histogram_quantile(
0.99,
sum by (le) (
rate(coredns_dns_request_duration_seconds_bucket[5m])
)
)NXDOMAIN 不一定是故障,有些应用会主动尝试多个域名。SERVFAIL 或请求耗时突然上涨时,更需要结合应用日志、Service、Endpoints 和 CoreDNS Pod 日志看。
四、Scheduler 和 Controller Manager
kubeadm 集群里 Scheduler、Controller Manager 通常是独立静态 Pod,也可以通过 ServiceMonitor 采集。K3s 里这些组件打包在 k3s server 进程中,默认暴露方式和 kubeadm 不一样。
在 K3s server 节点上可以查看监听端口:
bash
# 10257 通常对应 kube-controller-manager
# 10259 通常对应 kube-scheduler
ss -lntp | egrep ':(10257|10259)\b'当前轻量部署中没有启用 kubeControllerManager 和 kubeScheduler 的抓取,避免 Prometheus 出现一批长期 DOWN 的 target。要采集这两个组件,需要同时确认监听地址、证书、Service、Endpoints 和 ServiceMonitor。
K3s 场景里,调度和控制器异常可以从这些现象进入:
| 现象 | 入口 |
|---|---|
| Pod 长期 Pending | kubectl describe pod 查看调度事件 |
| Deployment 副本不上来 | kube_deployment_status_replicas_unavailable 和 Events |
| Job 不执行或失败 | kube_job_status_failed、CronJob 调度时间 |
| 控制器更新慢 | API Server 请求延迟、controller 日志、对象状态变化 |
五、排错入口
| 现象 | 检查入口 | 常见原因 |
|---|---|---|
apiserver target DOWN | Status -> Target health 展开 Last error | 证书、权限、ServiceMonitor、Endpoints 异常 |
coredns target DOWN | Status -> Target health 和 kubectl -n kube-system get pod | CoreDNS Pod 异常、ServiceMonitor 选择器不匹配 |
| PromQL 查询为空 | Prometheus Query、右上角时间范围、主机时间 | 指标不存在、时间范围不对、节点时间漂移 |
| API Server 5xx 增加 | apiserver_request_total{code=~"5.."} | API Server 内部异常、etcd 或 webhook 变慢 |
DNS NXDOMAIN 增加 | coredns_dns_responses_total{rcode="NXDOMAIN"} | Service 名、namespace、搜索域写错 |
DNS SERVFAIL 增加 | CoreDNS 日志和上游 DNS | 上游 DNS 异常、CoreDNS 插件异常 |
Prometheus 和浏览器时间差太大时,页面会出现 Server time is out of sync。查询结果看起来为空或时间错位时,主机时间同步也要纳入检查:
bash
# 查看当前时间源和同步状态
chronyc sources -v
# 查看系统时间、时区和 NTP 状态
timedatectl status