Appearance
etcd监控
自建 Kubernetes 控制平面通常需要把 etcd 作为核心监控对象。Pod、Deployment、Service、ConfigMap、Secret、Node 状态这些对象最终都会写入 etcd,API Server 读写对象时也要和 etcd 交互。etcd 变慢或失去多数派时,表现出来的可能不是某个业务 Pod 先异常,而是 API Server 请求变慢、对象写入失败、控制器状态更新延迟、集群操作卡住。
测试环境使用 K3s,默认数据存储是 SQLite,所以最初不会有 etcd target。真实 Kubernetes 控制平面需要监控 etcd,本次把三节点 K3s 从单 server SQLite 形态迁移成三 server embedded etcd 形态,再把 etcd 指标接入 Prometheus。
一、K3s 存储形态
K3s 可以使用几种数据存储方式。单 server K3s 默认用 SQLite,适合轻量环境;多 server 高可用场景通常使用 embedded etcd;也可以接外部 MySQL、PostgreSQL 或 etcd。
| 形态 | 说明 | 监控重点 |
|---|---|---|
| SQLite | 单 server K3s 默认方式,数据文件通常是 state.db | 文件存在、磁盘、K3s server 状态 |
| embedded etcd | K3s 内置 etcd,多 server 高可用常用形态 | leader、quorum、proposal、fsync、DB size、snapshot |
| external datastore | 外部数据库或外部 etcd | 外部存储本身的可用性、延迟、备份 |
基础集群原本是 k3s-server01 一台 server,加 k3s-agent01、k3s-agent02 两台 agent:
| 节点 | IP | 原角色 |
|---|---|---|
k3s-server01 | 192.168.10.11 | control-plane |
k3s-agent01 | 192.168.10.12 | agent |
k3s-agent02 | 192.168.10.13 | agent |
迁移前在 server 节点能看到 SQLite 数据文件:
bash
# SQLite 形态下,K3s server 数据库文件在 server/db 目录里
ls -l /var/lib/rancher/k3s/server/db输出里有 state.db、state.db-shm、state.db-wal,说明迁移前还不是 etcd 存储。
二、迁移为 embedded etcd
迁移过程分成三段:k3s-server01 初始化 embedded etcd,k3s-agent01 和 k3s-agent02 改成 server 加入集群,最后暴露 etcd metrics。
1. 初始化第一台 server
在 192.168.10.11 上保留原 systemd 配置备份,再通过 systemd drop-in 覆盖启动参数:
bash
stamp=$(date +%Y%m%d-%H%M%S)
mkdir -p /root/k3s-etcd-backup-$stamp
cp -a /etc/systemd/system/k3s.service /root/k3s-etcd-backup-$stamp/k3s.service.bak
mkdir -p /etc/systemd/system/k3s.service.d
cat >/etc/systemd/system/k3s.service.d/20-embedded-etcd.conf <<'EOF'
[Service]
ExecStart=
ExecStart=/usr/local/bin/k3s server \
--cluster-init \
--node-ip=192.168.10.11 \
--advertise-address=192.168.10.11 \
--write-kubeconfig-mode=644 \
--disable=traefik \
--etcd-expose-metrics
EOF
# 重新加载 systemd 后重启 k3s,让 SQLite 数据迁移到 embedded etcd
systemctl daemon-reload
systemctl restart k3s
systemctl is-active k3s--cluster-init 表示初始化一个新的 embedded etcd 集群。迁移完成后,k3s-server01 的角色会变成 control-plane,etcd:
bash
export KUBECONFIG=/etc/rancher/k3s/k3s.yaml
kubectl get nodes -o wide迁移后的数据目录会出现 etcd/,原来的 SQLite 文件会变成 state.db.migrated:
bash
find /var/lib/rancher/k3s/server/db -maxdepth 2 -type f -o -type d | sort关键变化如下:
text
/var/lib/rancher/k3s/server/db/etcd
/var/lib/rancher/k3s/server/db/etcd/member
/var/lib/rancher/k3s/server/db/state.db.migrated2. 另外两台 agent 改成 server
两台 agent 加入 embedded etcd 时需要使用 server 节点的 token:
bash
# 在 192.168.10.11 上查看 token,复制到 12 和 13 的 k3s.service.env
cat /var/lib/rancher/k3s/server/node-token192.168.10.12 上停止原来的 agent 服务,改成 k3s server:
bash
systemctl stop k3s-agent
systemctl disable k3s-agent
cat >/etc/systemd/system/k3s.service.env <<'EOF'
K3S_TOKEN="替换为 192.168.10.11 上的 node-token"
EOF
cat >/etc/systemd/system/k3s.service <<'EOF'
[Unit]
Description=Lightweight Kubernetes
Documentation=https://k3s.io
Wants=network-online.target
After=network-online.target
[Install]
WantedBy=multi-user.target
[Service]
Type=notify
EnvironmentFile=-/etc/default/%N
EnvironmentFile=-/etc/sysconfig/%N
EnvironmentFile=-/etc/systemd/system/k3s.service.env
KillMode=process
Delegate=yes
User=root
LimitNOFILE=1048576
LimitNPROC=infinity
LimitCORE=infinity
TasksMax=infinity
TimeoutStartSec=0
Restart=always
RestartSec=5s
ExecStartPre=-/sbin/modprobe br_netfilter
ExecStartPre=-/sbin/modprobe overlay
ExecStart=/usr/local/bin/k3s server \
--server https://192.168.10.11:6443 \
--node-ip=192.168.10.12 \
--advertise-address=192.168.10.12 \
--node-name=k3s-agent01 \
--write-kubeconfig-mode=644 \
--disable=traefik \
--etcd-expose-metrics
EOF
systemctl daemon-reload
systemctl enable --now k3s
systemctl is-active k3s192.168.10.13 使用相同配置,IP 和节点名换成本机:
| 参数 | 192.168.10.13 填写值 |
|---|---|
--node-ip | 192.168.10.13 |
--advertise-address | 192.168.10.13 |
--node-name | k3s-agent02 |
三台都启动后,节点角色如下:
text
NAME STATUS ROLES VERSION
k3s-agent01 Ready control-plane,etcd v1.35.5+k3s1
k3s-agent02 Ready control-plane,etcd v1.35.5+k3s1
k3s-server01 Ready control-plane,etcd v1.35.5+k3s1这时已经是三 server embedded etcd。三节点 etcd 最多容忍一个成员不可用;同时丢两台,quorum 不成立,控制平面就会出现读写异常。
三、暴露 etcd 指标
K3s embedded etcd 的 metrics 端口是 2381。未开启 --etcd-expose-metrics 时,2381 只监听在 127.0.0.1,Prometheus Pod 不能通过节点 IP 抓取。加上 --etcd-expose-metrics 后,可以看到 2381 同时监听在节点 IP 上:
bash
ss -lntp | grep 2381
# 本机访问 2381,确认能看到 etcd 指标
curl -s http://127.0.0.1:2381/metrics | grep -m3 '^etcd_'
# 通过节点 IP 访问,确认 Prometheus 也有机会抓到
curl -s http://192.168.10.11:2381/metrics | grep -m3 '^etcd_'输出里能看到这些指标:
text
etcd_cluster_version{cluster_version="3.6"} 1
etcd_debugging_auth_revision 1
etcd_disk_wal_fsync_duration_seconds_bucket{le="0.001"} ...--etcd-expose-metrics 只是暴露 metrics 端口,不等于暴露 etcd 客户端读写接口。生产环境里还要结合安全组、防火墙或 NetworkPolicy 控制访问范围,避免把控制平面指标端口直接暴露到无关网段。
四、接入 Prometheus
kube-prometheus-stack 默认没有自动识别 K3s embedded etcd。可以单独创建一个无 selector 的 Service,把三个节点的 2381 作为 Endpoints,再用 ServiceMonitor 让 Prometheus 抓取。
Kubernetes 当前版本会提示 v1 Endpoints 已进入弃用路线。这个环境里的 kube-prometheus-stack 生成的抓取配置仍使用 endpoints 发现角色,所以保留 Endpoints 写法;如果集群和 Prometheus Operator 已统一切到 EndpointSlice,需要同步确认 ServiceMonitor 的发现角色和 RBAC。
/root/monitoring/k3s-etcd-endpoints.yaml:
yaml
apiVersion: v1
kind: Service
metadata:
name: k3s-etcd
namespace: monitoring
labels:
app.kubernetes.io/name: k3s-etcd
app.kubernetes.io/component: datastore
spec:
clusterIP: None
ports:
- name: metrics
port: 2381
targetPort: 2381
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
name: k3s-etcd
namespace: monitoring
labels:
app.kubernetes.io/name: k3s-etcd
app.kubernetes.io/component: datastore
subsets:
- addresses:
- ip: 192.168.10.11
nodeName: k3s-server01
- ip: 192.168.10.12
nodeName: k3s-agent01
- ip: 192.168.10.13
nodeName: k3s-agent02
ports:
- name: metrics
port: 2381
protocol: TCP
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: k3s-etcd
namespace: monitoring
labels:
app.kubernetes.io/name: k3s-etcd
app.kubernetes.io/component: datastore
spec:
selector:
matchLabels:
app.kubernetes.io/name: k3s-etcd
namespaceSelector:
matchNames:
- monitoring
endpoints:
- port: metrics
scheme: http
interval: 30s
scrapeTimeout: 10s
path: /metrics
relabelings:
- sourceLabels: [__meta_kubernetes_endpoint_node_name]
targetLabel: node应用配置:
bash
kubectl apply -f /root/monitoring/k3s-etcd-endpoints.yaml
kubectl -n monitoring get svc,endpoints,servicemonitor k3s-etcd -o wideEndpoints 里能看到三个节点:
text
192.168.10.11:2381,192.168.10.12:2381,192.168.10.13:2381五、Target 验证
操作路径:
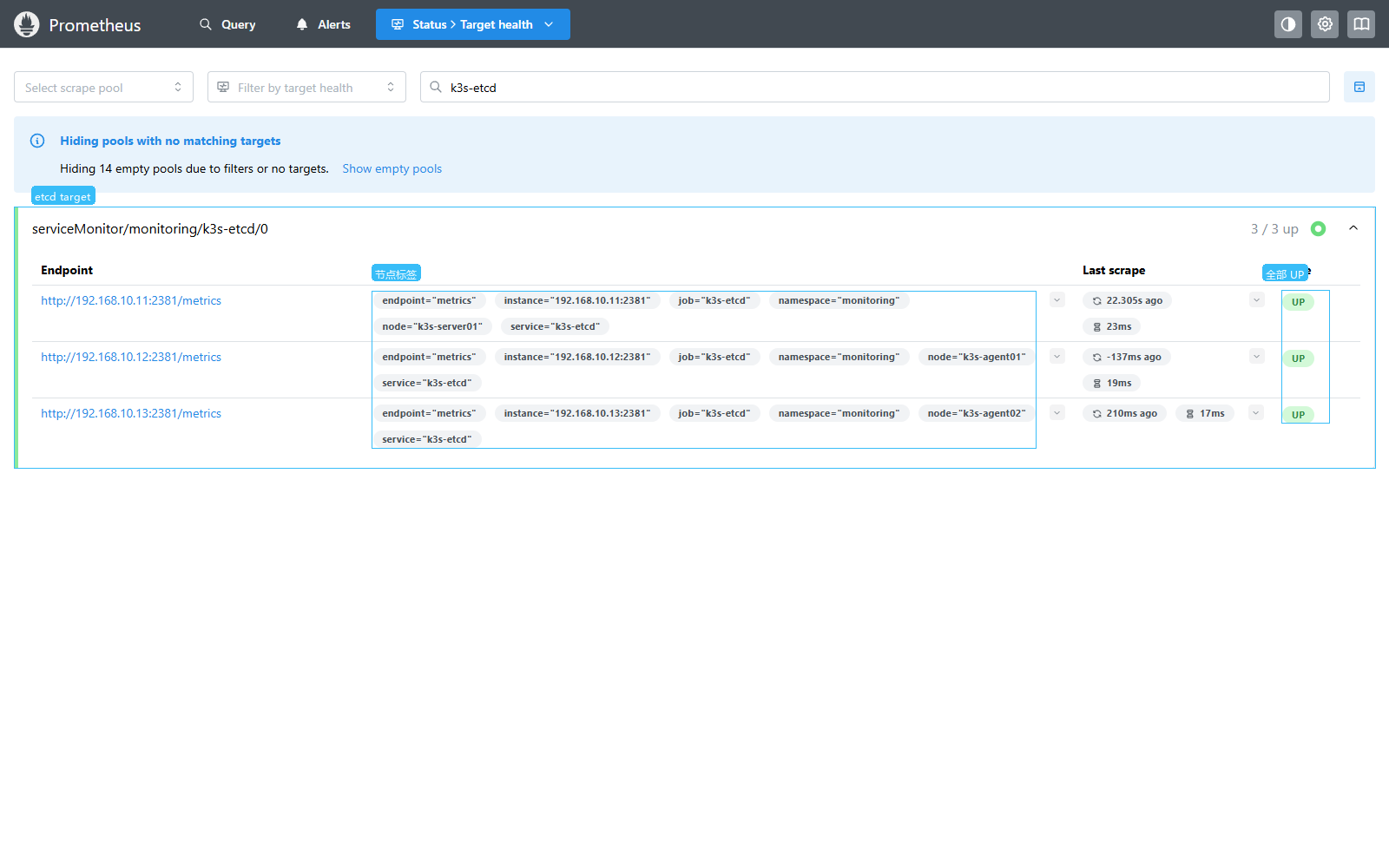
Status -> Target health (中文:状态 -> 目标健康)
在 Prometheus 里搜索 k3s-etcd。这个页面证明 Prometheus 已经通过 ServiceMonitor 找到三个 etcd metrics target,并且三台都是 UP。
命令行也可以从 Prometheus API 验证:
bash
curl -sG http://127.0.0.1:30900/api/v1/query \
--data-urlencode 'query=count(up{job="k3s-etcd"} == 1)'结果为 3,表示三台 etcd metrics target 都在 UP 状态。
六、核心指标
etcd 监控重点不是进程是否存在,而是共识状态、写入延迟、磁盘同步延迟和数据量变化。
| 方向 | 指标 | 含义 |
|---|---|---|
| leader | etcd_server_has_leader | 当前成员是否看到 leader |
| leader | etcd_server_is_leader | 当前成员自己是否是 leader |
| leader 变化 | etcd_server_leader_changes_seen_total | leader 切换次数 |
| proposal | etcd_server_proposals_committed_total | 成功提交的 proposal 总数 |
| proposal | etcd_server_proposals_failed_total | 失败的 proposal 总数 |
| WAL fsync | etcd_disk_wal_fsync_duration_seconds_bucket | WAL 刷盘耗时分布 |
| backend commit | etcd_disk_backend_commit_duration_seconds_bucket | 后端提交耗时分布 |
| DB size | etcd_mvcc_db_total_size_in_bytes | etcd 数据库大小 |
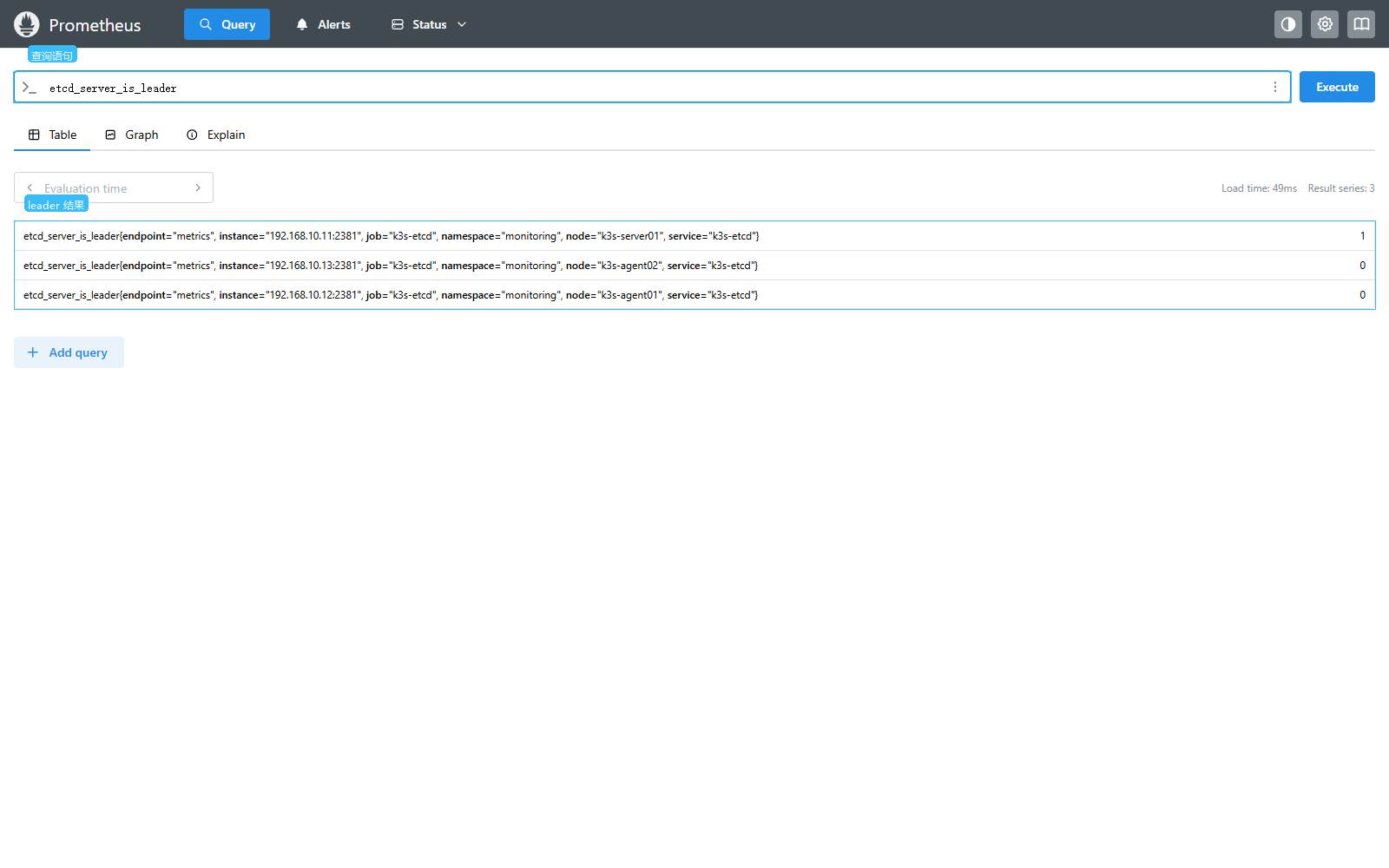
leader 查询:
promql
etcd_server_is_leader查询结果里 k3s-server01 为 1,另外两台为 0,表示 leader 在 k3s-server01:
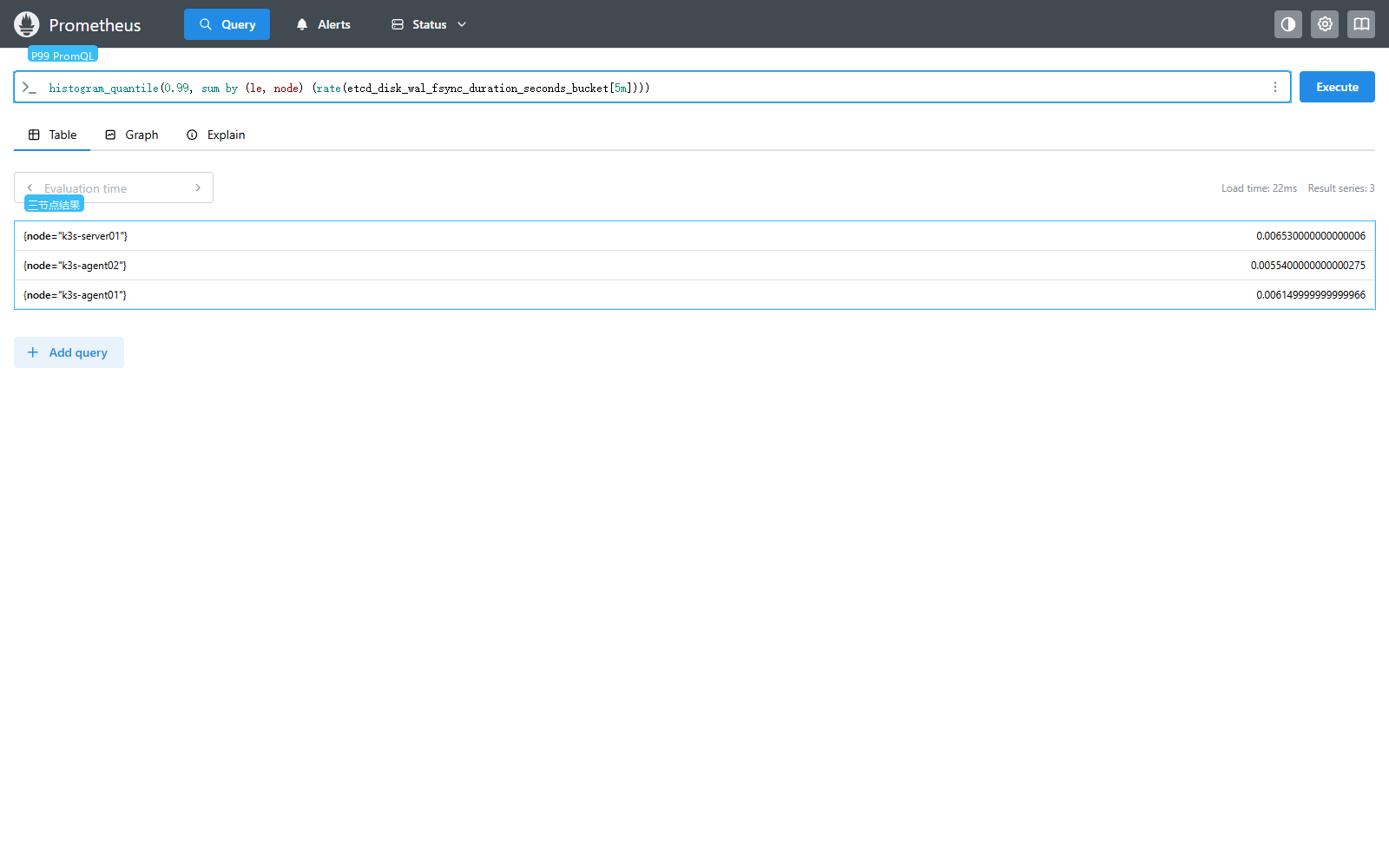
WAL fsync P99:
promql
histogram_quantile(
0.99,
sum by (le, node) (
rate(etcd_disk_wal_fsync_duration_seconds_bucket[5m])
)
)WAL 是 etcd 写入日志,fsync 表示把日志刷到磁盘。这个值升高时,API Server 写入对象的延迟也可能被拖高。
proposal 失败率:
promql
rate(etcd_server_proposals_failed_total[5m])DB size:
promql
etcd_mvcc_db_total_size_in_bytesbackend commit P99:
promql
histogram_quantile(
0.99,
sum by (le, node) (
rate(etcd_disk_backend_commit_duration_seconds_bucket[5m])
)
)本次 Prometheus 查询里,etcd_server_proposals_failed_total 三台都是 0,etcd_mvcc_db_total_size_in_bytes 大约 7MiB,WAL fsync 和 backend commit 的 P99 都在毫秒级。这个结果只能说明小环境状态正常,不能直接当生产阈值。
七、Grafana 看板验证
操作路径:
Dashboards -> K3s Etcd Monitoring Lab (中文:仪表盘 -> K3s Etcd Monitoring Lab)
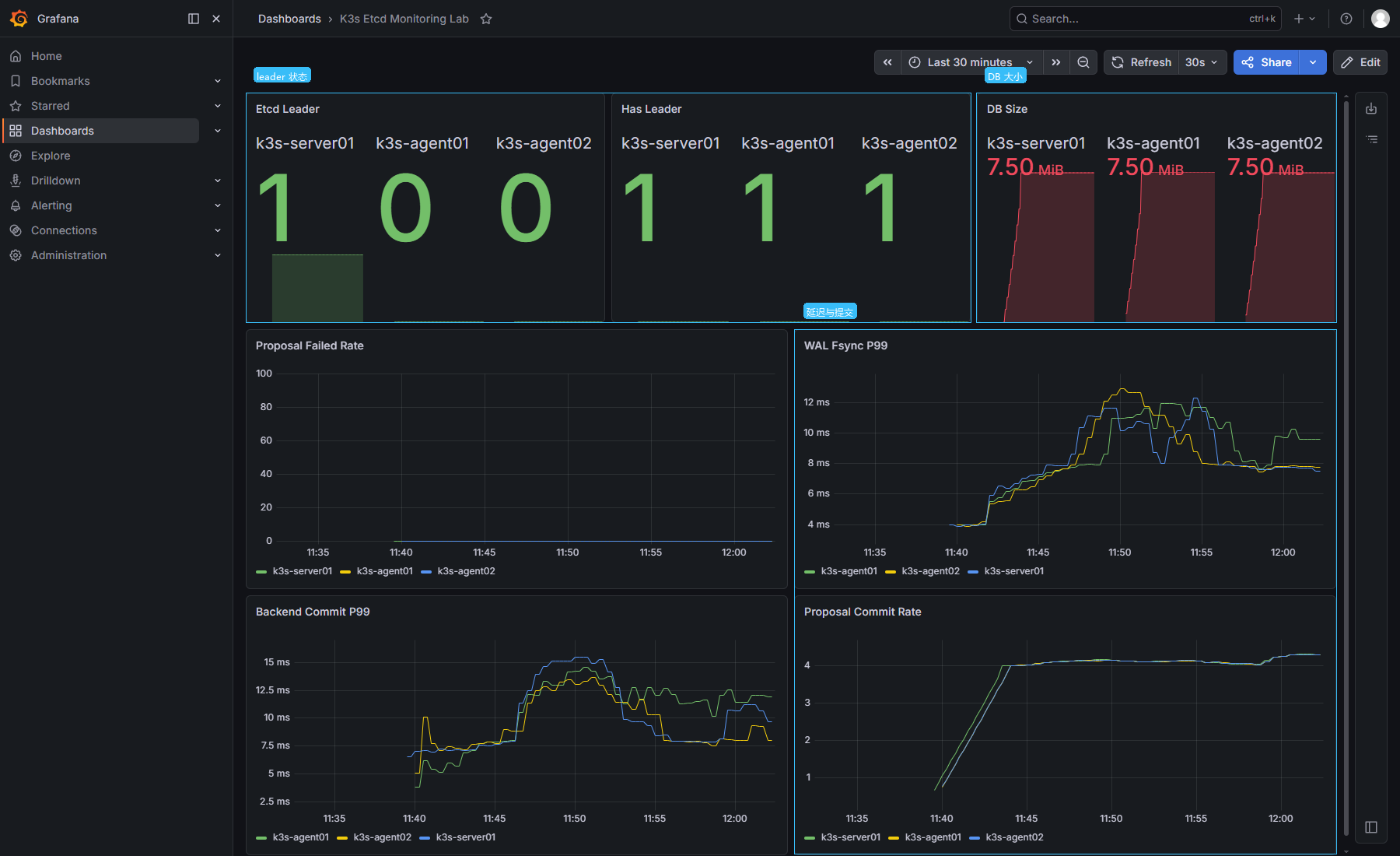
这个看板把 etcd 的几个关键状态放在同一屏里:当前 leader、三台成员是否都有 leader、DB size、proposal 失败率、WAL fsync P99、backend commit P99、proposal commit rate。
| 面板 | PromQL | 作用 |
|---|---|---|
| Etcd Leader | etcd_server_is_leader | 看当前 leader 在哪台节点 |
| Has Leader | etcd_server_has_leader | 看每个成员是否都能看到 leader |
| DB Size | etcd_mvcc_db_total_size_in_bytes | 看数据量和快照大小趋势 |
| Proposal Failed Rate | rate(etcd_server_proposals_failed_total[5m]) | 看共识提交是否失败 |
| WAL Fsync P99 | histogram_quantile(0.99, sum by (le, node) (rate(etcd_disk_wal_fsync_duration_seconds_bucket[5m]))) | 看 WAL 刷盘延迟 |
| Backend Commit P99 | histogram_quantile(0.99, sum by (le, node) (rate(etcd_disk_backend_commit_duration_seconds_bucket[5m]))) | 看后端提交延迟 |
| Proposal Commit Rate | rate(etcd_server_proposals_committed_total[5m]) | 看写入提交变化 |
看板里,k3s-server01 是 leader,三台成员的 Has Leader 都是 1,DB size 约 7.50MiB。WAL fsync 和 backend commit 曲线能看到毫秒级波动,proposal failed rate 保持在 0。
测试机资源比较紧,Grafana 初始 memory limit 是 384Mi,加载大屏时出现过 /api/health 超时。把 Grafana limit 调到 768Mi 后再截图:
bash
kubectl -n monitoring set resources deployment/kps-grafana \
--containers=grafana \
--requests=cpu=50m,memory=128Mi \
--limits=memory=768Mi
kubectl -n monitoring rollout status deployment/kps-grafana --timeout=180s这类调整不改变 etcd 采集链路,只是避免 Grafana 在小内存环境里加载看板时反复 readiness 抖动。
八、快照验证
etcd 监控和备份要放在一起看。指标能说明当前状态,快照能决定故障后能不能恢复。
手动保存一次快照:
bash
# 在 server 节点执行,快照默认保存在 server/db/snapshots 目录
k3s etcd-snapshot save --name etcd-monitoring-lab
# 查看最近的快照文件、大小和创建时间
k3s etcd-snapshot ls | tail -5本次输出:
text
Name Location Size Created
etcd-monitoring-lab-k3s-server01-1779940052 file:///var/lib/rancher/k3s/server/db/snapshots/etcd-monitoring-lab-k3s-server01-1779940052 7864352 2026-05-28T11:47:32+08:00快照文件约 7.5MiB。如果 DB size 持续增长,快照大小也会跟着变大,备份保留、磁盘容量和恢复耗时都要一起评估。
九、告警方向
etcd 告警通常关注这些方向:
| 告警方向 | PromQL 方向 |
|---|---|
| 无 leader | etcd_server_has_leader == 0 |
| leader 频繁变化 | increase(etcd_server_leader_changes_seen_total[15m]) > 3 |
| proposal 失败 | rate(etcd_server_proposals_failed_total[5m]) > 0 |
| WAL fsync 延迟升高 | WAL fsync P99 持续升高 |
| backend commit 延迟升高 | backend commit P99 持续升高 |
| DB size 持续增长 | etcd_mvcc_db_total_size_in_bytes 按时间增长过快 |
etcd 属于控制平面核心组件。告警阈值需要结合集群规模、磁盘类型、API Server 请求量和日常波动调整;小实验环境里的毫秒级结果,只适合验证采集链路和理解指标含义。