Appearance
K8s对象监控
K8s 对象监控主要依赖 kube-state-metrics。它读取 Kubernetes API 里的对象状态,再把这些状态转成 Prometheus 指标。它关心的是“声明状态”和“实际状态”是否一致,而不是容器实际用了多少 CPU 或内存。
比如 Deployment 声明要 3 个副本,实际可用只有 2 个;PVC 声明需要绑定存储,但一直是 Pending;CronJob 到时间没有执行。这类问题都属于对象状态问题。
一、kube-state-metrics
kube-state-metrics 是 Kubernetes API 状态的指标出口。它不直接管理 Pod,也不改变集群对象,只负责把对象字段转换成指标。
常见对象和指标关系:
| 对象 | 指标方向 |
|---|---|
| Node | Ready、MemoryPressure、DiskPressure、PIDPressure |
| Deployment | 期望副本、可用副本、更新副本、不可用副本 |
| Pod | phase、waiting reason、restart count、container ready |
| PVC | Bound、Pending、Lost |
| Job | succeeded、failed、active |
| CronJob | 下次调度时间、是否暂停 |
Prometheus 里验证 kube-state-metrics:
操作路径:
Query -> Table (中文:查询 -> 表格)
操作步骤:
- 进入 Prometheus
Query。 - 选择
Table。 - 输入
sum by (namespace, pod) (kube_pod_info)。 - 点击
Execute。
promql
sum by (namespace, pod) (
kube_pod_info
)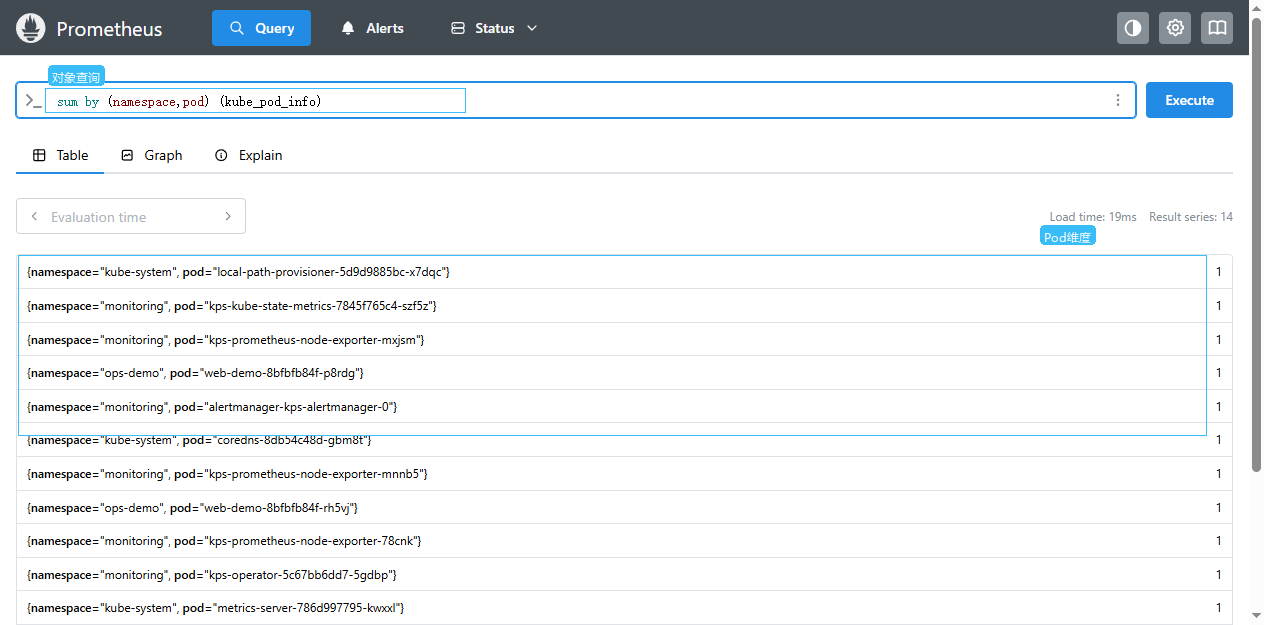
kube_pod_info 这类指标本身的值通常是 1,重点不在数值,而在它携带的标签:namespace、pod、node、created_by_kind 等。对象监控里经常通过标签聚合和过滤来定位异常对象。
二、Node 对象
Node 对象状态来自 kubelet 上报到 API Server 的 Node Condition。节点资源使用率来自 node-exporter 或 kubelet/cAdvisor,节点是否 Ready、是否有磁盘压力则来自 kube-state-metrics。
常用查询:
promql
# 节点 Ready 状态
kube_node_status_condition{condition="Ready", status="true"}
# 节点压力状态
kube_node_status_condition{
condition=~"MemoryPressure|DiskPressure|PIDPressure",
status="true"
}
# 节点数量
count(kube_node_info)Grafana 节点对象视图:
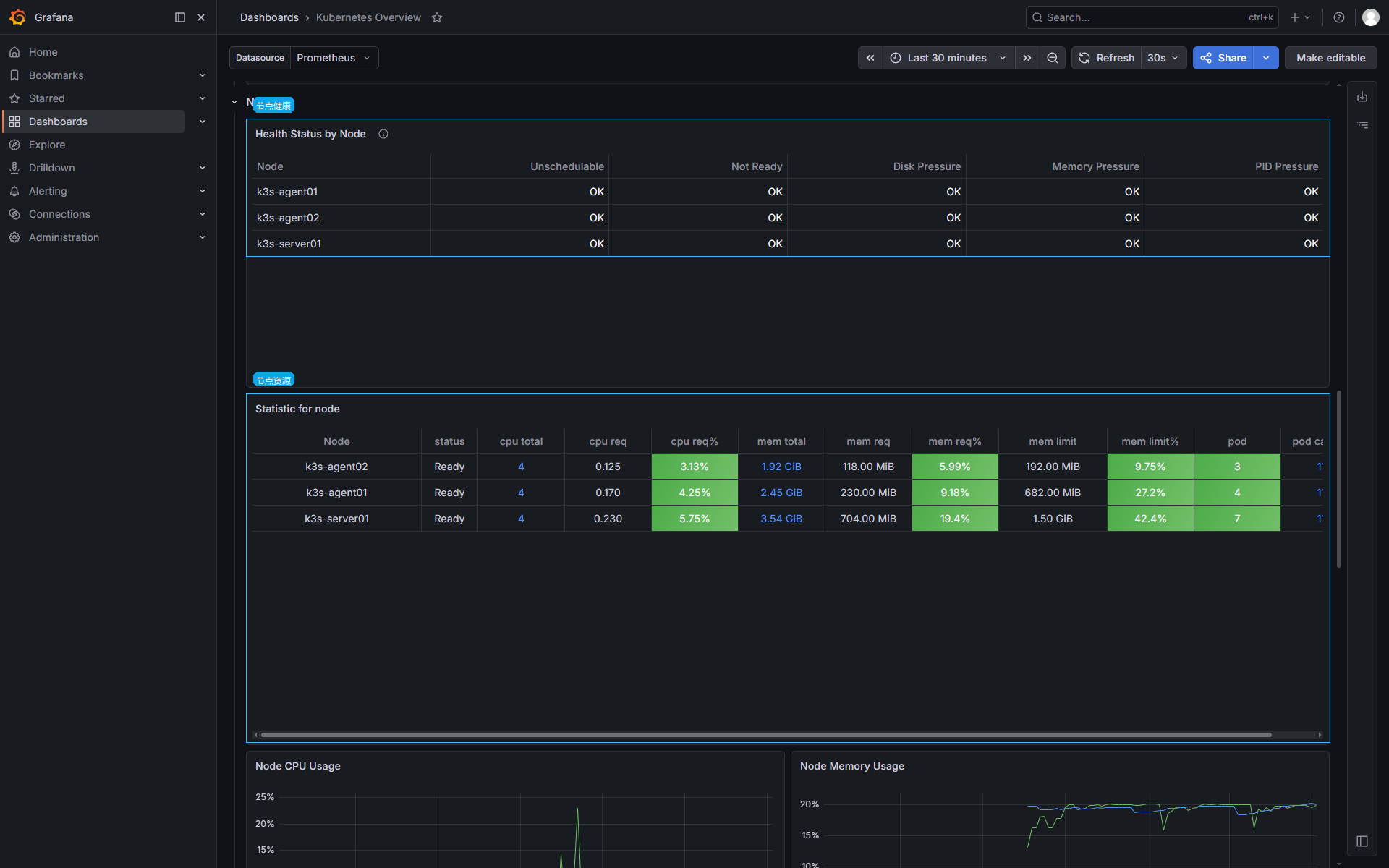
Node 对象异常和主机资源指标要一起看。DiskPressure=True 表示 kubelet 已经判断节点磁盘压力异常;具体是根分区、镜像目录、容器日志还是 local-path PV 占满,还要回到 node-exporter 的文件系统指标和节点磁盘目录。
三、Deployment 对象
Deployment 监控的核心是副本状态。发布后最常见的对象问题是期望副本和可用副本不一致。
常用查询:
promql
# Deployment 可用副本小于期望副本
kube_deployment_status_replicas_available
<
kube_deployment_spec_replicas
# 按 namespace / deployment 查看副本缺口
sum by (namespace, deployment) (
kube_deployment_spec_replicas
-
kube_deployment_status_replicas_available
)
# 不可用副本
kube_deployment_status_replicas_unavailableGrafana 里可以用 kube-state-metrics-v2 模板查看 Deployment 副本状态:
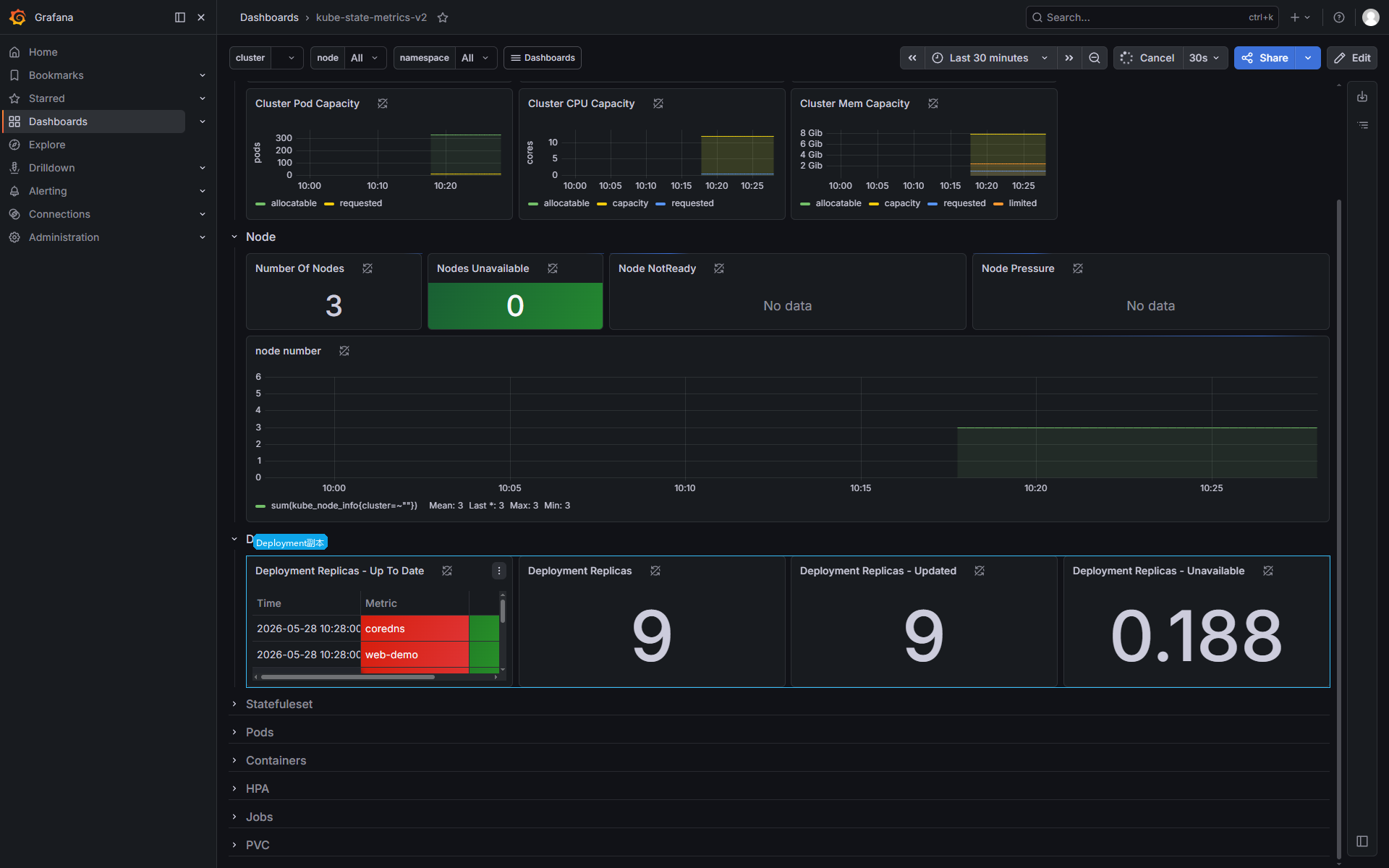
Deployment 不可用副本出现时,排查路径通常是:
bash
# 查看 Deployment 的期望副本、可用副本和镜像
kubectl -n <namespace> get deploy <deployment-name> -o wide
# 查看 ReplicaSet 和 Pod 是否创建出来
kubectl -n <namespace> get rs,pod -l app=<app-label> -o wide
# Events 会记录镜像拉取失败、调度失败、探针失败等原因
kubectl -n <namespace> describe deploy <deployment-name>四、Pod 对象
Pod 对象监控分成 phase、waiting reason、restart count 和 ready 状态。Pod Running 不代表业务一定正常,但 Pending、Failed、Unknown 通常需要进一步处理。
常用查询:
promql
# Pod phase
sum by (namespace, pod, phase) (
kube_pod_status_phase
)
# 容器等待原因
kube_pod_container_status_waiting_reason
# 最近 15 分钟容器重启次数
increase(kube_pod_container_status_restarts_total[15m])
# 容器 ready 状态
kube_pod_container_status_readynamespace 维度的 Pod 状态适合做第一层定位:
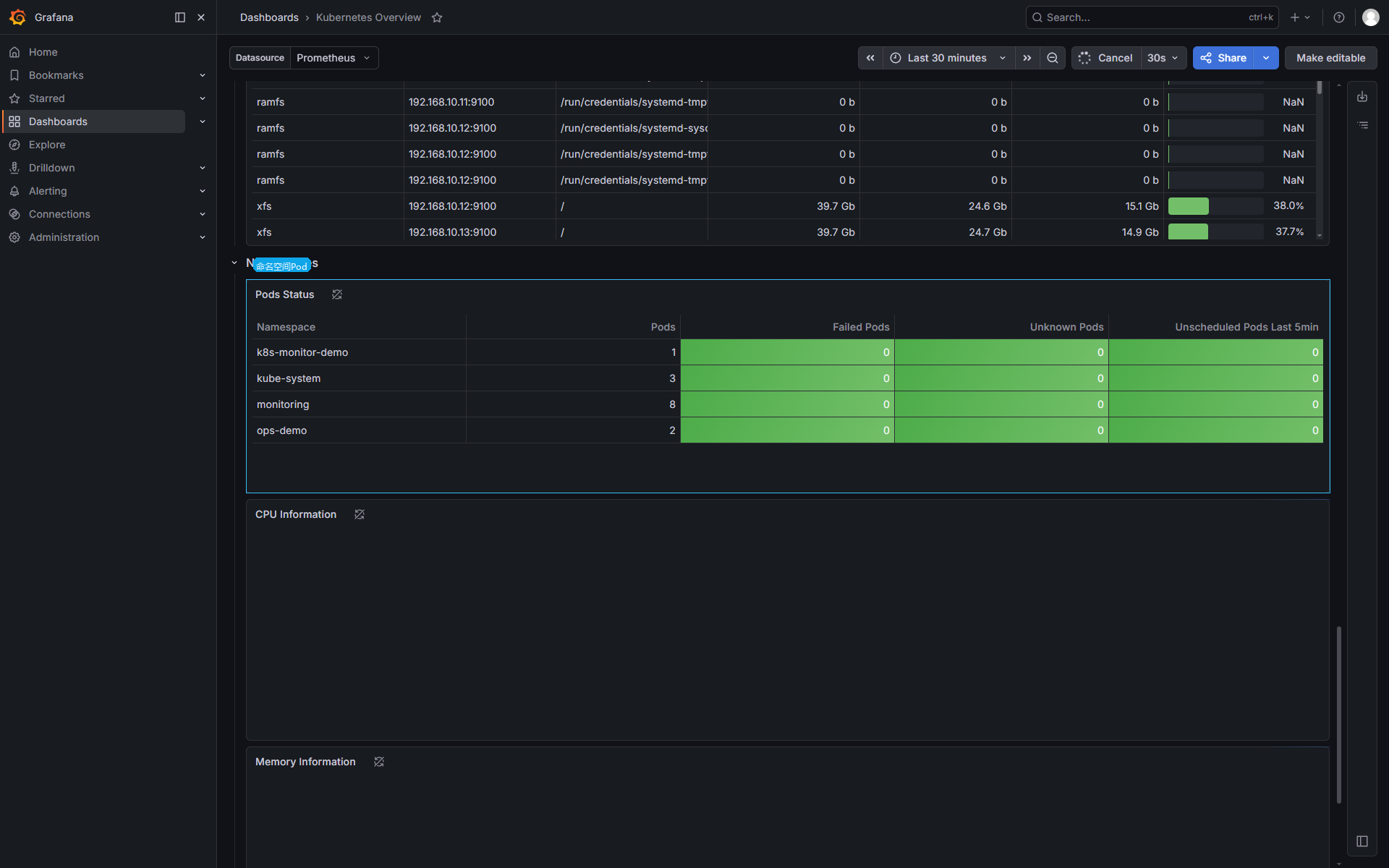
常见 waiting reason:
| reason | 说明 | 常见入口 |
|---|---|---|
ImagePullBackOff | 镜像拉取失败 | 镜像地址、凭据、镜像源、网络 |
CrashLoopBackOff | 容器反复退出 | 容器日志、启动命令、配置 |
CreateContainerConfigError | 容器配置异常 | ConfigMap、Secret、环境变量、挂载 |
ContainerCreating | 容器创建中 | 镜像、CNI、存储挂载 |
Pod 状态异常时,Prometheus 指标负责指出“哪个对象异常”,具体原因通常在 Events 和容器日志里:
bash
# 查看异常 Pod
kubectl get pod -A \
--field-selector=status.phase!=Running,status.phase!=Succeeded \
-o wide
# 查看 Events 和容器状态
kubectl -n <namespace> describe pod <pod-name>
# 查看容器日志
kubectl -n <namespace> logs <pod-name> -c <container-name> --tail=100五、PVC 对象
PVC 代表 Pod 申请的持久化存储。对象层面先看 PVC 是否 Bound;容量和使用率则来自 kubelet volume stats 或存储系统自身指标。
常用查询:
promql
# PVC 状态
kube_persistentvolumeclaim_status_phase
# PVC 未绑定
kube_persistentvolumeclaim_status_phase{phase!="Bound"} == 1
# PVC 可用比例
kubelet_volume_stats_available_bytes
/
kubelet_volume_stats_capacity_bytesK3s 默认 local-path provisioner 使用节点本地路径。它适合轻量组件和临时环境,但 Pod 漂移到其他节点时,本地数据不会跟着漂移。生产数据服务通常要接 NFS、Ceph RBD、Longhorn、云盘 CSI 这类后端。
PVC Pending 常见方向:
| 现象 | 检查入口 |
|---|---|
| PVC 一直 Pending | kubectl describe pvc |
| StorageClass 不存在 | kubectl get storageclass |
| provisioner 异常 | provisioner Pod 日志 |
| PV 权限或容量异常 | 存储后端和 PV 事件 |
六、Job 和 CronJob
Job/CronJob 常用于备份、巡检、定时清理和批处理任务。它们不适合只看 Pod Running,因为 Job 正常完成后 Pod 会退出,关键是成功次数、失败次数和最近调度时间。
常用查询:
promql
# Job 失败
kube_job_status_failed > 0
# Job 成功
kube_job_status_succeeded
# Job 当前仍在执行
kube_job_status_active
# CronJob 下次调度时间
kube_cronjob_next_schedule_timeCronJob 排查入口:
bash
# 查看 CronJob 是否暂停、最近调度时间和当前 Job
kubectl -n <namespace> get cronjob
# 查看 Job 成功/失败数量
kubectl -n <namespace> get job
# 查看 Job 对应 Pod 的事件和日志
kubectl -n <namespace> describe job <job-name>七、对象监控排查路径
对象监控适合从异常状态进入,再回到 Kubernetes 原生命令确认原因。
| 指标发现 | 下一步 |
|---|---|
| Node NotReady | kubectl describe node,再看 kubelet 和节点资源 |
| Deployment 副本不足 | 查 ReplicaSet、Pod、Events |
| Pod Pending | 查调度事件、节点资源、PVC、污点和节点选择器 |
| Pod 重启增加 | 查容器日志、退出码、探针配置 |
| PVC Pending | 查 StorageClass、PV、provisioner 和存储后端 |
| Job failed | 查 Job Events、Pod 日志、退出码 |
对象指标给出的是“状态变化”,不是完整故障原因。Prometheus、Grafana、kubectl describe 和日志要连在一起看,排查链路才完整。