Appearance
应用指标接入
K8s 里的应用接入 Prometheus,通常是应用暴露 /metrics,再通过 ServiceMonitor 或 PodMonitor 让 Prometheus 自动发现。平台指标能说明 Pod、节点和对象状态,应用指标更接近业务运行本身,例如请求量、错误率、延迟、队列长度、任务积压和业务开关状态。
ServiceMonitor 的关系:Prometheus 不直接去找 Pod,而是先根据 ServiceMonitor 找 Service,再通过 Service 的 Endpoints 找到后端 Pod。这里最容易出错的是标签和端口名:selector.matchLabels 匹配的是 Service 标签,endpoints.port 写的是 Service 端口名,不是数字端口。
一、Demo 指标应用
当前环境里用一个很小的 BusyBox Pod 暴露静态指标,镜像使用节点上已经存在的 busybox:1.38.0,避免为了演示接入流程再拉一个额外镜像。Prometheus 3 对 /metrics 响应头比较严格,目标返回空 Content-Type 时会被拒绝,所以这里用 nc 手动返回 Prometheus 文本格式的响应头。
/root/monitoring/k8s-monitor-demo.yaml:
yaml
apiVersion: v1
kind: Namespace
metadata:
name: k8s-monitor-demo
---
apiVersion: v1
kind: ConfigMap
metadata:
name: demo-metrics-page
namespace: k8s-monitor-demo
data:
metrics: |
# HELP demo_requests_total Demo request counter for ServiceMonitor test.
# TYPE demo_requests_total counter
demo_requests_total{app="demo-metrics",code="200"} 1024
# HELP demo_queue_depth Demo queue depth for Grafana panel test.
# TYPE demo_queue_depth gauge
demo_queue_depth{app="demo-metrics"} 7
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo-metrics
namespace: k8s-monitor-demo
labels:
app: demo-metrics
spec:
replicas: 1
selector:
matchLabels:
app: demo-metrics
template:
metadata:
labels:
app: demo-metrics
spec:
containers:
- name: demo
image: busybox:1.38.0
imagePullPolicy: IfNotPresent
command:
- sh
- -c
- |
# Prometheus 3 会校验 scrape 响应格式,这里显式返回 text/plain 头
while true; do
{
printf 'HTTP/1.1 200 OK\r\n'
printf 'Content-Type: text/plain; version=0.0.4; charset=utf-8\r\n'
printf 'Connection: close\r\n\r\n'
cat /metrics-data/metrics
} | nc -l -p 8080
done
ports:
- name: metrics
containerPort: 8080
volumeMounts:
- name: metrics-page
mountPath: /metrics-data/metrics
subPath: metrics
resources:
requests:
cpu: 5m
memory: 16Mi
limits:
memory: 64Mi
volumes:
- name: metrics-page
configMap:
name: demo-metrics-page
---
apiVersion: v1
kind: Service
metadata:
name: demo-metrics
namespace: k8s-monitor-demo
labels:
app: demo-metrics
spec:
selector:
app: demo-metrics
ports:
- name: metrics
port: 8080
targetPort: metrics部署后先看 Pod、Service 和 Endpoints:
bash
export KUBECONFIG=/etc/rancher/k3s/k3s.yaml
kubectl apply -f /root/monitoring/k8s-monitor-demo.yaml
kubectl -n k8s-monitor-demo rollout status deploy/demo-metrics --timeout=180s
kubectl -n k8s-monitor-demo get pod,svc,endpoints -o wide本次结果里,Service 已经指向后端 Pod:
text
NAME READY STATUS IP
pod/demo-metrics-8546f59879-ssgm2 1/1 Running 10.42.1.40
NAME TYPE CLUSTER-IP PORT(S)
service/demo-metrics ClusterIP 10.43.80.226 8080/TCP
NAME ENDPOINTS
endpoints/demo-metrics 10.42.1.40:8080先在 Pod 内确认 /metrics 响应格式。这里看响应头比只看内容更有意义:
bash
kubectl -n k8s-monitor-demo exec deploy/demo-metrics -- sh -c \
'printf "GET /metrics HTTP/1.1\r\nHost: localhost\r\n\r\n" | nc 127.0.0.1 8080 | sed -n "1,12p"'关键输出:
text
HTTP/1.1 200 OK
Content-Type: text/plain; version=0.0.4; charset=utf-8
# HELP demo_requests_total Demo request counter for ServiceMonitor test.
# TYPE demo_requests_total counter
demo_requests_total{app="demo-metrics",code="200"} 1024遇到过一次 target 已经被发现但状态是 DOWN,错误是 non-compliant scrape target sending blank Content-Type。这种情况不是 ServiceMonitor 标签问题,而是应用 /metrics 响应头不符合 Prometheus 3 的要求。
二、ServiceMonitor
kube-prometheus-stack 通过 Prometheus Operator 管理 Prometheus,ServiceMonitor 是 Operator 提供的 CRD。当前 Prometheus values 里已经放开 selector:
yaml
prometheus:
prometheusSpec:
serviceMonitorSelectorNilUsesHelmValues: false
podMonitorSelectorNilUsesHelmValues: false这表示新增的 ServiceMonitor 不需要额外打 Helm release 标签,也可以被当前 Prometheus 选择到。
在同一个 YAML 里追加 ServiceMonitor:
yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: demo-metrics
namespace: monitoring
labels:
app: demo-metrics
spec:
namespaceSelector:
matchNames:
- k8s-monitor-demo
selector:
matchLabels:
app: demo-metrics
endpoints:
- port: metrics
path: /metrics
interval: 60s字段关系:
| 字段 | 当前值 | 说明 |
|---|---|---|
metadata.namespace | monitoring | ServiceMonitor 对象放在监控命名空间 |
namespaceSelector.matchNames | k8s-monitor-demo | 去哪个 namespace 找 Service |
selector.matchLabels | app: demo-metrics | 匹配 Service 上的标签 |
endpoints.port | metrics | Service 端口名,必须和 Service 里的 ports.name 一致 |
endpoints.path | /metrics | 应用暴露指标的路径 |
应用 ServiceMonitor:
bash
kubectl apply -f /root/monitoring/k8s-monitor-demo.yaml
kubectl -n monitoring get servicemonitor demo-metrics -o yaml三、Prometheus 查看
操作路径:
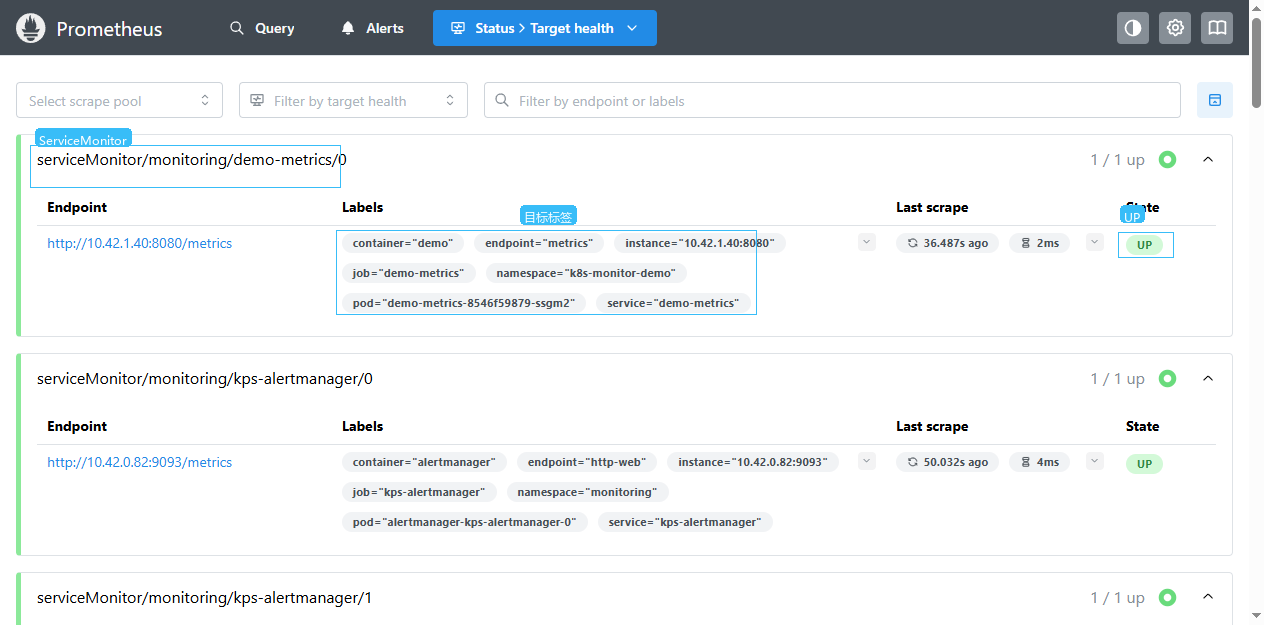
Status -> Target health (中文:状态 -> 目标健康)
打开 http://192.168.10.11:30900/targets,过滤或查找 serviceMonitor/monitoring/demo-metrics/0。页面里需要同时看到三件事:scrape pool 名称、目标 labels、State 是 UP。
操作路径:
Query -> Table (中文:查询 -> 表格)
查询 demo 指标:
promql
demo_requests_total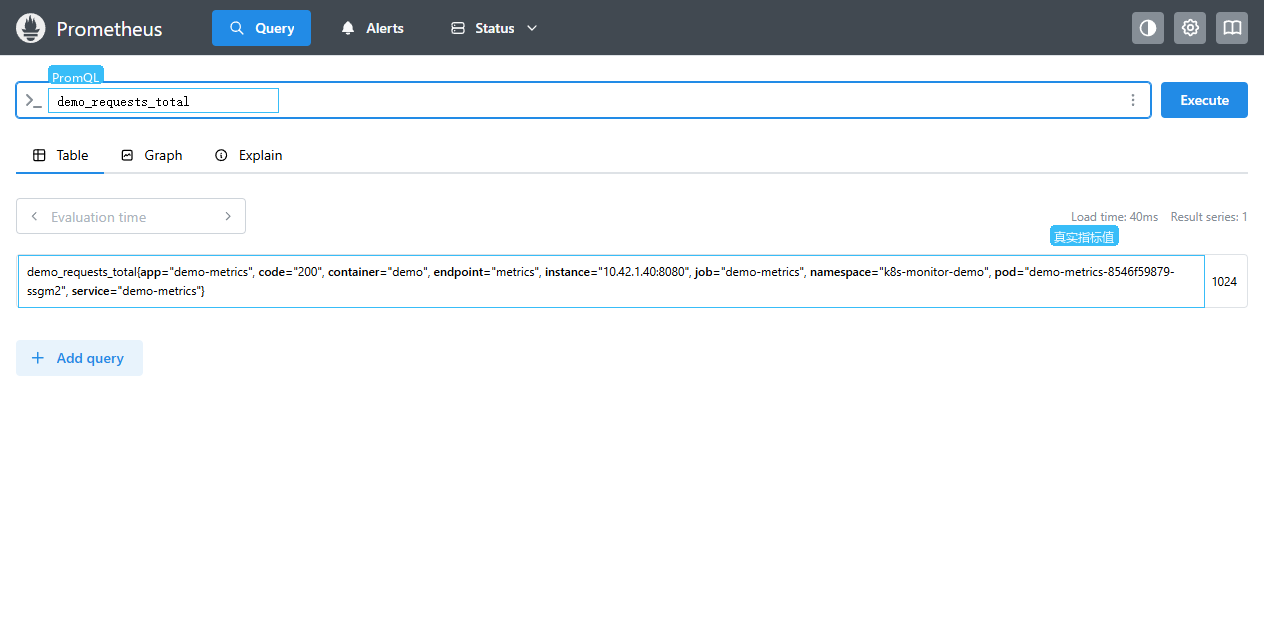
命令行也可以查同样的数据:
bash
curl -sG http://127.0.0.1:30900/api/v1/query \
--data-urlencode 'query=demo_requests_total'up 查询适合确认抓取状态:
promql
up{namespace="k8s-monitor-demo", service="demo-metrics"}本次结果里 up 是 1,demo_requests_total 是 1024,demo_queue_depth 是 7。
四、排错入口
应用指标接入失败时,按对象关系往回查,比只看 Prometheus 页面更清楚。
| 现象 | 检查入口 | 常见原因 |
|---|---|---|
| Prometheus Targets 没有 demo | kubectl -n monitoring get servicemonitor demo-metrics -o yaml | ServiceMonitor 没创建、namespace 不对、Prometheus selector 没选中 |
target 出现但是 DOWN | Prometheus Status -> Target health 的 Last error | /metrics 路径错误、响应头不合规、Pod 端口不通 |
| target 没有 endpoint | kubectl -n k8s-monitor-demo get endpoints demo-metrics -o wide | Service selector 没匹配 Pod 标签 |
| ServiceMonitor 存在但不抓取 | 对照 Service 的 labels 和 ports.name | selector.matchLabels 或 endpoints.port 写错 |
| 指标值查不到 | Prometheus Query 和 Pod 内 nc/curl | 应用没有输出该指标,或者指标名写错 |
镜像拉取失败也会影响接入。本次环境统一使用 docker.1ms.run 作为 docker.io mirror;之前多 mirror 配置里有源返回 429 Too Many Requests,Pod 会卡在 ImagePullBackOff。这类问题看 kubectl describe pod 的 Events 比看 Prometheus 更直接。
五、标签设计
应用指标常见标签:
| 标签 | 说明 |
|---|---|
namespace | 所属 namespace,K8s 场景里通常由 Prometheus 采集链路自动补上 |
pod | Pod 名,适合排查单个副本问题 |
service | Service 名,适合按服务聚合 |
app | 应用名,适合跨 Pod 聚合 |
env | 环境,例如 prod、staging、test |
method | HTTP 方法 |
code | HTTP 状态码 |
route | 路由模板,例如 /api/users/:id |
user_id、request_id、trace_id 不适合作为普通指标标签。它们变化太多,会让时间序列数量膨胀。TraceID 更适合放在日志和链路追踪里;指标和 Trace 的关联通常用 exemplar。