Appearance
K8s告警规则
K8s 告警关注的是集群对象和组件的持续异常。Pod 重建、滚动发布、镜像拉取、调度等待都会让指标短时间变化,告警规则要把正常波动和真正影响服务的状态区分开。节点 NotReady、Pod 反复重启、Deployment 可用副本不足、PVC 剩余空间偏低、API Server 错误率升高,才是监控里更常见的告警对象。
Prometheus Operator 使用 PrometheusRule 管理规则。PrometheusRule 写入 Kubernetes API 后,由 Operator 校验并转换成 Prometheus 能读取的规则文件;Prometheus 定期加载规则、计算表达式,再把进入 Firing 的告警发送到 Alertmanager。
一、规则来自哪些指标
K8s 告警不是直接读 kubectl get pod 的结果,而是使用监控组件暴露出来的指标。
| 指标来源 | 常见指标 | 适合告警的状态 |
|---|---|---|
| kube-state-metrics | kube_deployment_status_replicas_available、kube_pod_container_status_restarts_total、kube_node_status_condition | 对象期望状态和当前状态不一致 |
| kubelet / cAdvisor | container_cpu_usage_seconds_total、container_memory_working_set_bytes、kubelet_volume_stats_available_bytes | 容器资源、PVC 容量、节点采集状态 |
| API Server | apiserver_request_total、apiserver_request_duration_seconds_bucket | API 错误率、请求延迟 |
| etcd | etcd_server_has_leader、etcd_disk_wal_fsync_duration_seconds_bucket | 控制平面存储状态 |
kube-state-metrics 更像 Kubernetes 对象状态的导出器。Deployment 期望几个副本、实际可用几个副本,Pod 当前是不是 CrashLoopBackOff,Node 是否 Ready,这些状态经常由它提供。kubelet 更贴近节点和容器运行时,PVC 容量、容器资源、cAdvisor 指标通常来自这一侧。
告警排查时经常要把 PromQL 和 Kubernetes 对象对起来看。例如 K8sDeploymentReplicasUnavailable 触发后,Prometheus 只能说明 deployment 的可用副本不足;真正原因可能是调度失败、镜像拉取失败、探针失败、容器启动失败、资源不足,还要回到 kubectl describe pod/deployment 和事件里确认。
二、测试对象
当前环境基于三节点 K3s 集群,监控栈部署过程参考 K3s部署监控栈。真实 K8s 告警链路用两个异常对象观察:
| 对象 | 异常方式 | 对应告警 |
|---|---|---|
crash-loop-app | 容器启动后退出,Pod 进入 CrashLoopBackOff | K8sPodCrashLooping、K8sPodRestartingTooMuch、K8sDeploymentReplicasUnavailable |
replica-shortage-app | nodeSelector 指向不存在的节点,两个 Pod 无法调度 | K8sDeploymentReplicasUnavailable |
/root/monitoring/k8s-real-alerts.yaml:
yaml
apiVersion: v1
kind: Namespace
metadata:
name: k8s-alert-case
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: crash-loop-app
namespace: k8s-alert-case
labels:
app: crash-loop-app
spec:
replicas: 1
selector:
matchLabels:
app: crash-loop-app
template:
metadata:
labels:
app: crash-loop-app
spec:
containers:
- name: app
image: busybox:1.38.0
command:
- sh
- -c
- |
# 模拟应用启动失败,kubelet 会不断重启容器。
echo "simulate app start failure"
exit 1
resources:
requests:
cpu: 10m
memory: 16Mi
limits:
memory: 32Mi
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: replica-shortage-app
namespace: k8s-alert-case
labels:
app: replica-shortage-app
spec:
replicas: 2
selector:
matchLabels:
app: replica-shortage-app
template:
metadata:
labels:
app: replica-shortage-app
spec:
# 指向不存在的节点名,用来制造 Pending 和可用副本不足。
nodeSelector:
kubernetes.io/hostname: no-such-node
containers:
- name: app
image: busybox:1.38.0
command:
- sh
- -c
- sleep 3600
resources:
requests:
cpu: 10m
memory: 16Mi
limits:
memory: 32Mi应用后查看对象状态:
bash
export KUBECONFIG=/etc/rancher/k3s/k3s.yaml
kubectl apply -f /root/monitoring/k8s-real-alerts.yaml
kubectl -n k8s-alert-case get pod,deploy -o wide命令结果里,crash-loop-app 的 Pod 是 CrashLoopBackOff,replica-shortage-app 的两个 Pod 是 Pending:
text
NAME READY STATUS RESTARTS
pod/crash-loop-app-6f58b5f7f5-f8jrg 0/1 CrashLoopBackOff 5
pod/replica-shortage-app-67c46c5cf-qq8s9 0/1 Pending 0
pod/replica-shortage-app-67c46c5cf-zlv9t 0/1 Pending 0
NAME READY UP-TO-DATE AVAILABLE
deployment.apps/crash-loop-app 0/1 1 0
deployment.apps/replica-shortage-app 0/2 2 0三、PrometheusRule
告警规则同样放在 /root/monitoring/k8s-real-alerts.yaml:
yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: k8s-real-alerts
namespace: monitoring
labels:
app.kubernetes.io/name: k8s-real-alerts
spec:
groups:
- name: k8s-real.rules
rules:
- alert: K8sNodeNotReady
expr: kube_node_status_condition{condition="Ready", status="true"} == 0
for: 3m
labels:
severity: critical
category: kubernetes
annotations:
summary: "Kubernetes node is not Ready"
description: "node={{ $labels.node }} has not been Ready for 3 minutes."
- alert: K8sPodCrashLooping
expr: kube_pod_container_status_waiting_reason{reason="CrashLoopBackOff"} == 1
for: 1m
labels:
severity: warning
category: kubernetes
annotations:
summary: "Pod container is CrashLoopBackOff"
description: "namespace={{ $labels.namespace }}, pod={{ $labels.pod }}, container={{ $labels.container }}."
- alert: K8sPodRestartingTooMuch
expr: increase(kube_pod_container_status_restarts_total[15m]) > 3
for: 1m
labels:
severity: warning
category: kubernetes
annotations:
summary: "Pod container restarts too much"
description: "namespace={{ $labels.namespace }}, pod={{ $labels.pod }}, container={{ $labels.container }}, restarts={{ $value }}."
- alert: K8sDeploymentReplicasUnavailable
expr: (kube_deployment_spec_replicas - kube_deployment_status_replicas_available) > 0
for: 1m
labels:
severity: warning
category: kubernetes
annotations:
summary: "Deployment available replicas are lower than expected"
description: "namespace={{ $labels.namespace }}, deployment={{ $labels.deployment }}, unavailable={{ $value }}."
- alert: K8sPVCSpaceLow
expr: (kubelet_volume_stats_available_bytes / kubelet_volume_stats_capacity_bytes) < 0.15
for: 5m
labels:
severity: warning
category: kubernetes
annotations:
summary: "PVC available space is low"
description: "namespace={{ $labels.namespace }}, pvc={{ $labels.persistentvolumeclaim }}, available ratio={{ $value }}."关键字段:
| 字段 | 说明 |
|---|---|
groups.name | Prometheus 页面里的规则组名称,排查时经常按它定位规则文件 |
alert | 告警名,进入 Alertmanager 后会变成 alertname 标签 |
expr | PromQL 表达式,返回非空并且值满足条件时进入 Pending |
for | 条件持续多久才进入 Firing,避免短暂波动直接报警 |
labels.severity | 告警级别,常用于 Alertmanager 路由 |
labels.category | 加上 kubernetes 分类,方便过滤 K8s 告警 |
annotations.summary | 告警摘要,适合放一句话现象 |
annotations.description | 告警详情,适合放 namespace、pod、deployment、当前值等排查字段 |
应用规则并确认 Operator 校验:
bash
kubectl apply -f /root/monitoring/k8s-real-alerts.yaml
kubectl -n monitoring get prometheusrule k8s-real-alerts \
-o jsonpath='{.metadata.annotations.prometheus-operator-validated}'
echo输出为 true,说明 Prometheus Operator 已经接受规则。
四、规则加载验证
操作路径:
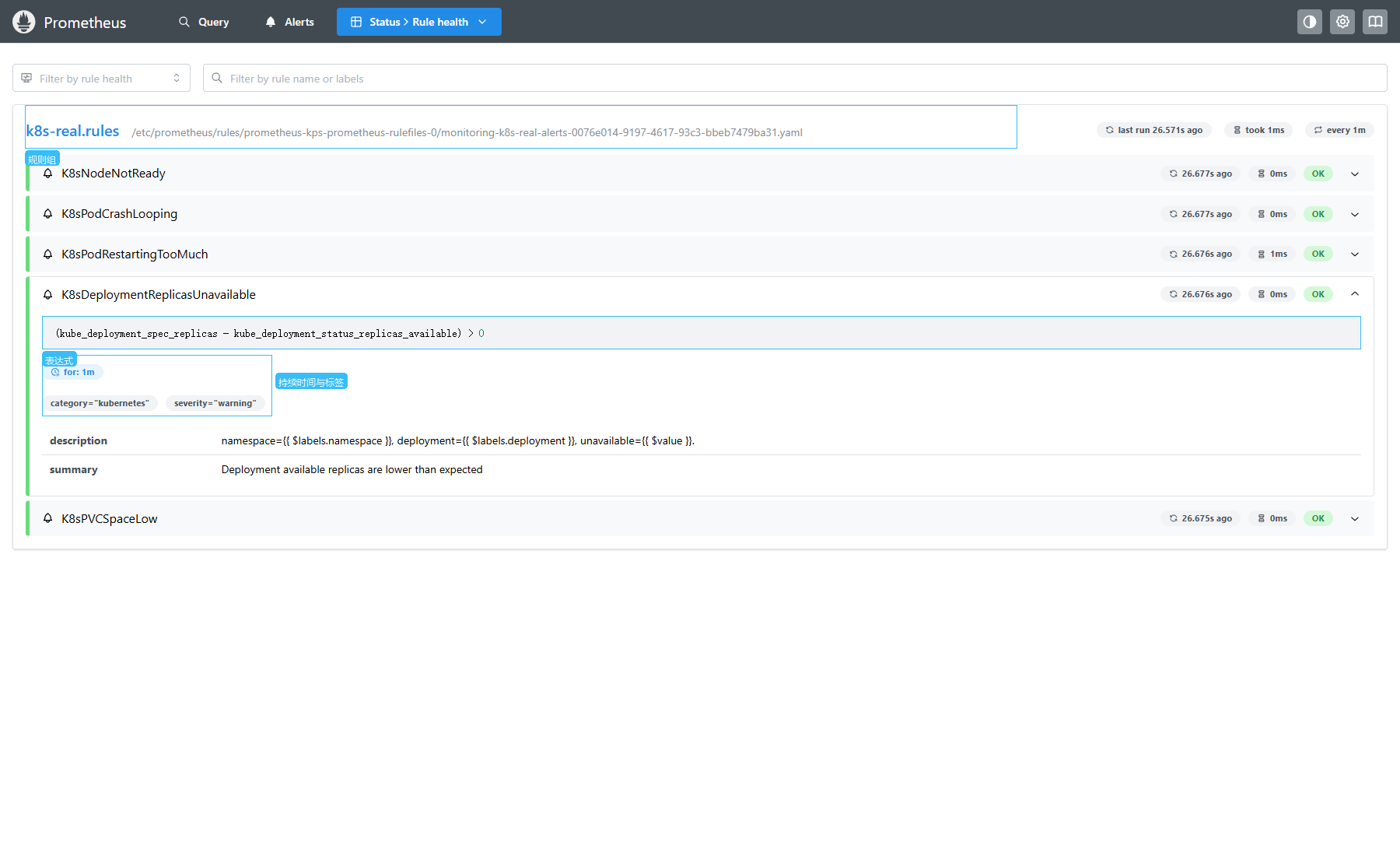
Status -> Rule health (中文:状态 -> 规则健康)
操作步骤:
- 打开
http://192.168.10.11:30900/rules。 - 在规则列表里找到
k8s-real.rules。 - 展开
K8sDeploymentReplicasUnavailable,查看表达式、for时间、标签和注解。
验证重点:
| 页面字段 | 当前值 | 含义 |
|---|---|---|
| Rule group | k8s-real.rules | Prometheus 已加载规则组 |
| Rule health | OK | 最近一次规则计算没有语法错误 |
| Expression | (kube_deployment_spec_replicas - kube_deployment_status_replicas_available) > 0 | 可用副本低于期望副本时触发 |
| Labels | category="kubernetes"、severity="warning" | Alertmanager 后续可按标签分组和路由 |
排错入口:
bash
kubectl -n monitoring get prometheusrule k8s-real-alerts -o yaml
kubectl -n monitoring logs deploy/kps-operator
kubectl -n monitoring logs prometheus-kps-prometheus-0 -c prometheus规则不存在,通常先看 PrometheusRule 是否被创建;规则存在但页面没有加载,继续看 Operator 日志和 Prometheus 日志。表达式写错时,Rules 页面通常能看到 unhealthy 状态或解析错误。
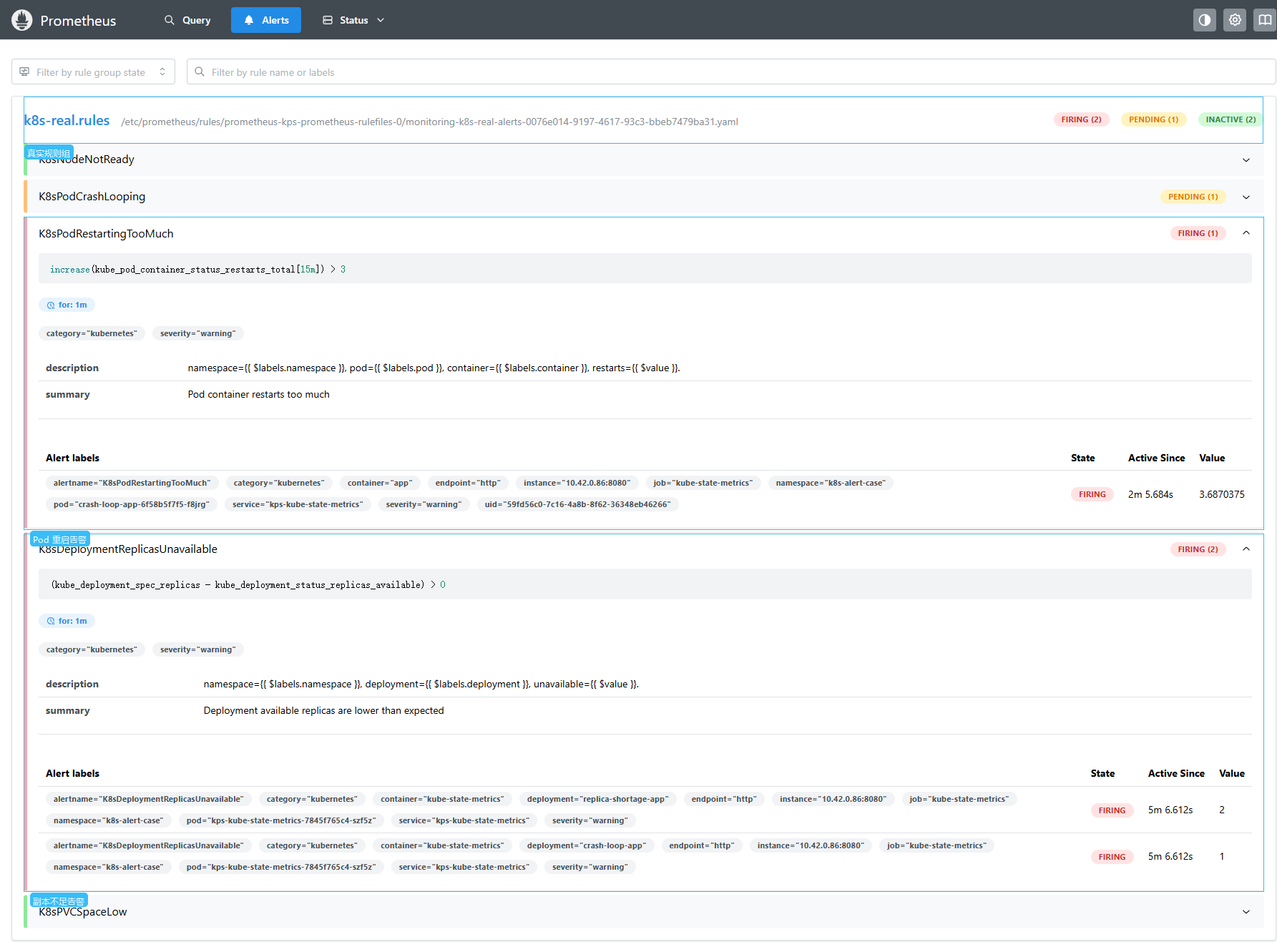
五、告警状态验证
操作路径:
Alerts (中文:告警)
操作步骤:
- 打开
http://192.168.10.11:30900/alerts。 - 展开
K8sPodRestartingTooMuch,查看 Pod 重启告警的表达式、标签、当前值和 Firing 状态。 - 展开
K8sDeploymentReplicasUnavailable,查看两个 Deployment 的副本不足告警。
验证重点:
| 告警 | 状态 | 当前对象 |
|---|---|---|
K8sPodRestartingTooMuch | FIRING | pod="crash-loop-app-6f58b5f7f5-f8jrg" |
K8sDeploymentReplicasUnavailable | FIRING | deployment="crash-loop-app"、deployment="replica-shortage-app" |
K8sPodCrashLooping | PENDING 或 FIRING | 取决于 kube-state-metrics 抓取到 CrashLoopBackOff 状态后的持续时间 |
命令行查询:
bash
curl -sG http://127.0.0.1:30900/api/v1/query \
--data-urlencode 'query=ALERTS{namespace="k8s-alert-case"}'返回结果能看到 alertstate="firing" 的 K8sPodRestartingTooMuch 和 K8sDeploymentReplicasUnavailable。K8sPodCrashLooping 依赖 kube_pod_container_status_waiting_reason{reason="CrashLoopBackOff"},Pod 状态在 Error 和 CrashLoopBackOff 之间切换时,可能会比重启次数告警更不稳定。
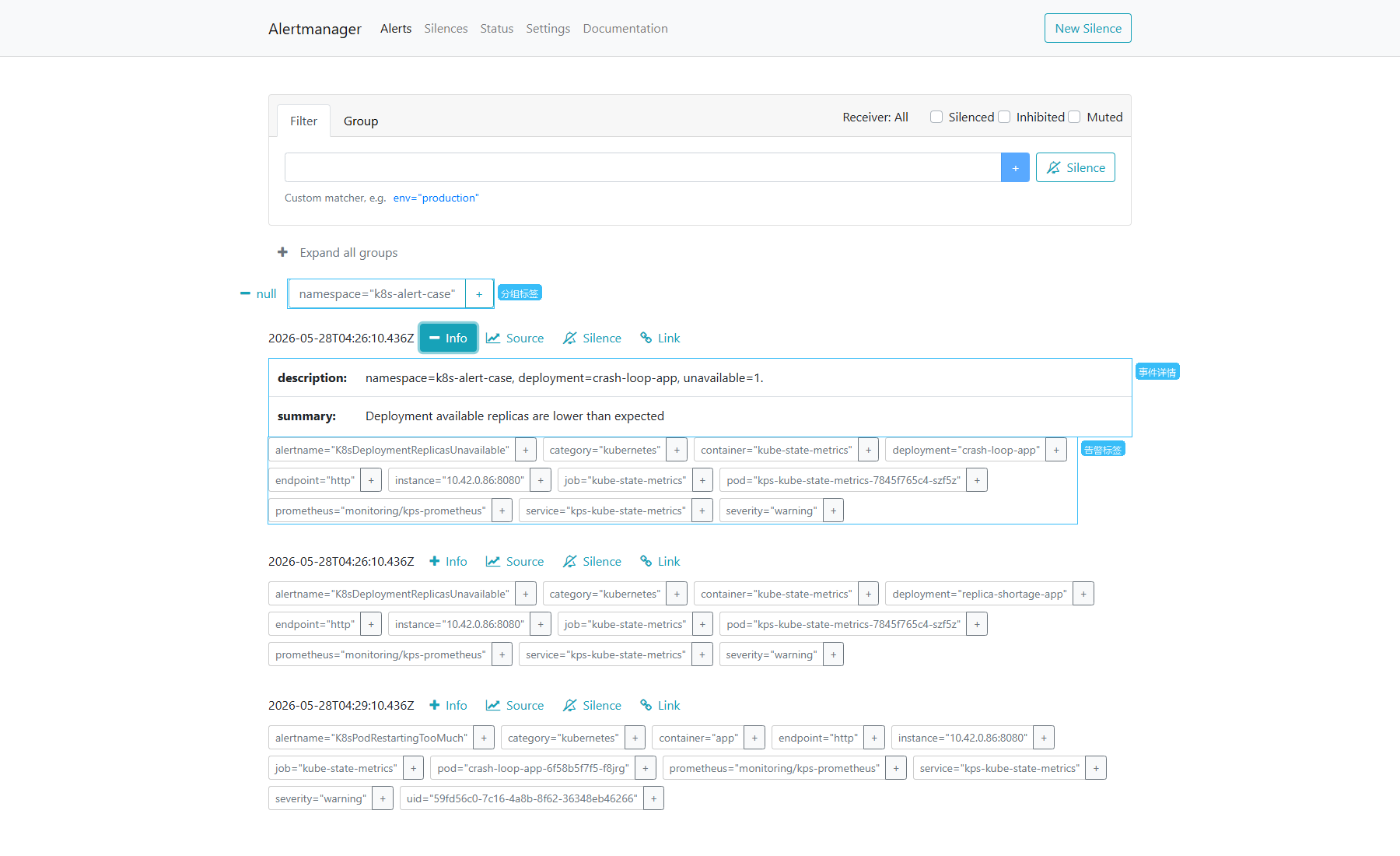
六、Alertmanager 验证
操作路径:
Alerts -> Group -> Info (中文:告警 -> 分组 -> 信息)
操作步骤:
- 打开
http://192.168.10.11:30903/#/alerts。 - 在分组里查看
namespace="k8s-alert-case"。 - 点击某条告警旁边的
Info。 - 查看
description、summary、alertname、category、deployment、severity等标签。
验证重点:
| 页面字段 | 当前值 | 说明 |
|---|---|---|
| 分组标签 | namespace="k8s-alert-case" | Alertmanager 按 namespace 聚合当前告警 |
description | deployment=crash-loop-app, unavailable=1 | 告警正文能直接看到异常对象和当前值 |
alertname | K8sDeploymentReplicasUnavailable | Prometheus 规则名已经流转到 Alertmanager |
severity | warning | 后续通知路由可按级别匹配 |
API 查询:
bash
curl -s http://127.0.0.1:30903/api/v2/alerts | grep k8s-alert-caseAlertmanager 有告警但没有对外通知时,继续检查 Status 里的路由配置、receiver、静默和抑制状态。当前环境 receiver 是 null,只表示告警已进入 Alertmanager,不代表已经配置短信、邮件、飞书或企业微信。
七、常用规则理解
1. 节点 NotReady
promql
kube_node_status_condition{condition="Ready", status="true"} == 0kube_node_status_condition 来自 kube-state-metrics。condition="Ready" 表示节点 Ready 条件,status="true" 表示 Ready 为真。值等于 0 时,说明节点没有处于 Ready 状态。
这类告警通常保留 node 标签。排查入口是:
bash
kubectl get nodes -o wide
kubectl describe node <node-name>
kubectl get events -A --sort-by=.lastTimestamp | tail -502. Pod CrashLoopBackOff
promql
kube_pod_container_status_waiting_reason{reason="CrashLoopBackOff"} == 1CrashLoopBackOff 表示容器启动后失败退出,kubelet 正在按退避时间重启它。这个告警能说明 Pod 当前处于等待重启状态,但采样时机可能受 Pod 状态切换影响。实际排查还要看上一轮容器退出原因、退出码和事件:
bash
kubectl -n k8s-alert-case describe pod <pod-name>
kubectl -n k8s-alert-case logs <pod-name> -c app --previous本次 crash-loop-app 的事件里能看到:
text
Back-off restarting failed container app3. Pod 重启过多
promql
increase(kube_pod_container_status_restarts_total[15m]) > 3kube_pod_container_status_restarts_total 是容器重启总次数。increase(...[15m]) > 3 表示最近 15 分钟重启次数增加超过 3 次。相比只看 CrashLoopBackOff,这条规则对“反复失败但状态瞬间切换”的情况更稳。
通知里适合保留 namespace、pod、container。缺少这些标签时,收到告警还要回 Prometheus 里查对象,排查会慢一截。
4. Deployment 可用副本不足
promql
(
kube_deployment_spec_replicas
-
kube_deployment_status_replicas_available
) > 0kube_deployment_spec_replicas 是期望副本数,kube_deployment_status_replicas_available 是当前可用副本数。两者相减大于 0,说明有副本没有变成 Available。
这个告警比较适合做服务可用性兜底,但它不直接说明原因。常见原因包括镜像拉取失败、调度失败、探针失败、容器启动失败、资源不足。排查入口:
bash
kubectl -n k8s-alert-case describe deploy replica-shortage-app
kubectl -n k8s-alert-case get pods -o wide
kubectl -n k8s-alert-case describe pod <pod-name>本次 replica-shortage-app 的 nodeSelector 指向不存在的节点,两个 Pod 处于 Pending,所以可用副本是 0/2。
5. PVC 空间不足
promql
(
kubelet_volume_stats_available_bytes
/
kubelet_volume_stats_capacity_bytes
) < 0.15PVC 空间指标来自 kubelet。available / capacity 小于 0.15 表示剩余空间低于 15%。这条规则需要集群里有真实 PVC,并且 kubelet 能采集到卷容量。存储类不同,指标可见性也会有差异。
排查入口:
bash
kubectl get pvc -A
kubectl describe pvc -n <namespace> <pvc-name>
kubectl get pv如果 PromQL 没有数据,常见原因是没有挂载中的 PVC、CSI 没有暴露容量信息、kubelet 没采集到 kubelet_volume_stats_*。
八、排查表
| 现象 | 检查入口 | 常见原因 | 处理方向 |
|---|---|---|---|
| Rules 页面没有规则 | kubectl -n monitoring get prometheusrule | 规则没有创建、namespace 写错、selector 没选中 | 修正 YAML 后重新 apply,查看 Operator 日志 |
| Rules 页面 unhealthy | Prometheus Status -> Rule health | PromQL 语法错误、指标名写错 | 在 Query 页面单独执行表达式,修正后观察加载状态 |
| Alerts 长期 Inactive | Prometheus Query | 表达式结果为空、标签过滤过窄 | 去掉部分标签逐步查询,确认指标真实标签 |
| 一直 Pending | for 时间、表达式结果变化 | 条件没有持续满足、指标采样时断时续 | 调整 for 或换成更稳定的指标组合 |
| Prometheus Firing,Alertmanager 没有 | Prometheus targets、Alertmanager API | Alertmanager 地址异常、告警发送失败 | 查看 Prometheus 配置和 Alertmanager Pod 日志 |
| Alertmanager 有告警,没有通知 | Alertmanager Status、receiver 配置 | 路由没匹配、receiver 是 null、被静默或抑制 | 检查 route、receiver、silence、inhibit_rules |
| 告警信息看不出对象 | Alertmanager labels、annotations | 规则没有保留 namespace、pod、deployment 等标签 | 调整表达式聚合方式和 annotations 内容 |
K8s 告警规则写完后,至少要经过三层验证:Prometheus 是否加载规则,Prometheus 是否计算出 Pending/Firing,Alertmanager 是否收到带完整标签的事件。只有 YAML 存在,说明不了告警链路已经可用。