Appearance
节点组件监控
K8s 节点监控包含两层:Linux 主机本身,以及节点上的 Kubernetes 组件。主机 CPU、内存、磁盘、网络来自 node-exporter;kubelet、探针、volume 和容器资源来自 kubelet/cAdvisor;节点 Ready、DiskPressure、Pod 数量这类对象状态来自 kube-state-metrics。
节点看起来 CPU、内存正常,Pod 仍然可能因为镜像拉取、探针失败、磁盘压力、CNI 或挂载异常变得不稳定。节点监控要把主机资源、kubelet 状态、容器资源和对象状态放在一起看。
一、Prometheus Target
操作路径:
Status -> Target health (中文:状态 -> 目标健康)
节点相关 target 主要有三类:
| scrape pool | 指标来源 |
|---|---|
kps-prometheus-node-exporter | Linux 主机资源 |
kps-kubelet/0 | kubelet /metrics |
kps-kubelet/1 | kubelet /metrics/cadvisor,容器资源 |
kps-kubelet/2 | kubelet /metrics/probes,探针指标 |
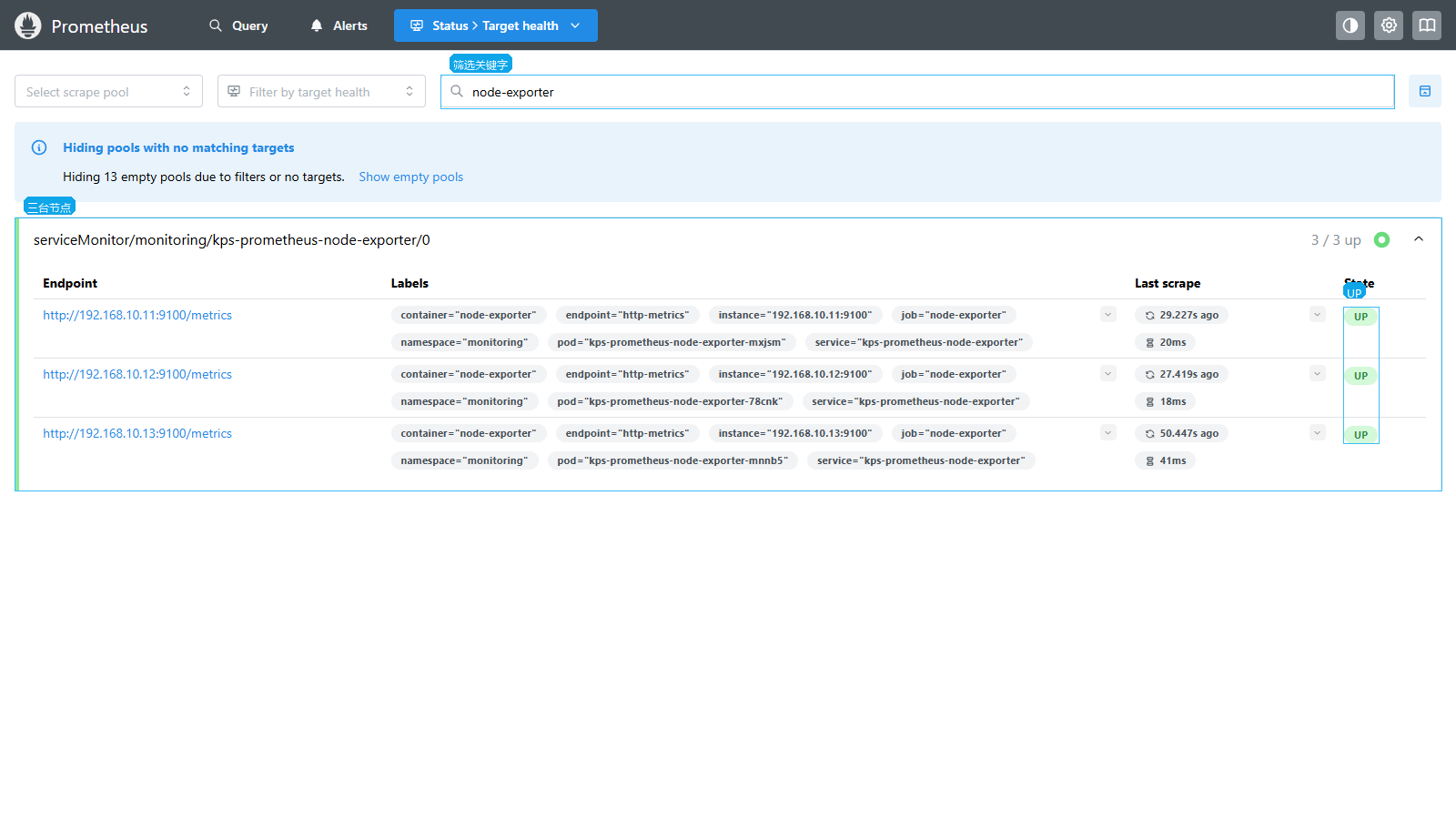
node-exporter 三台节点都为 UP:
kubelet target 包含 /metrics 和 /metrics/cadvisor:
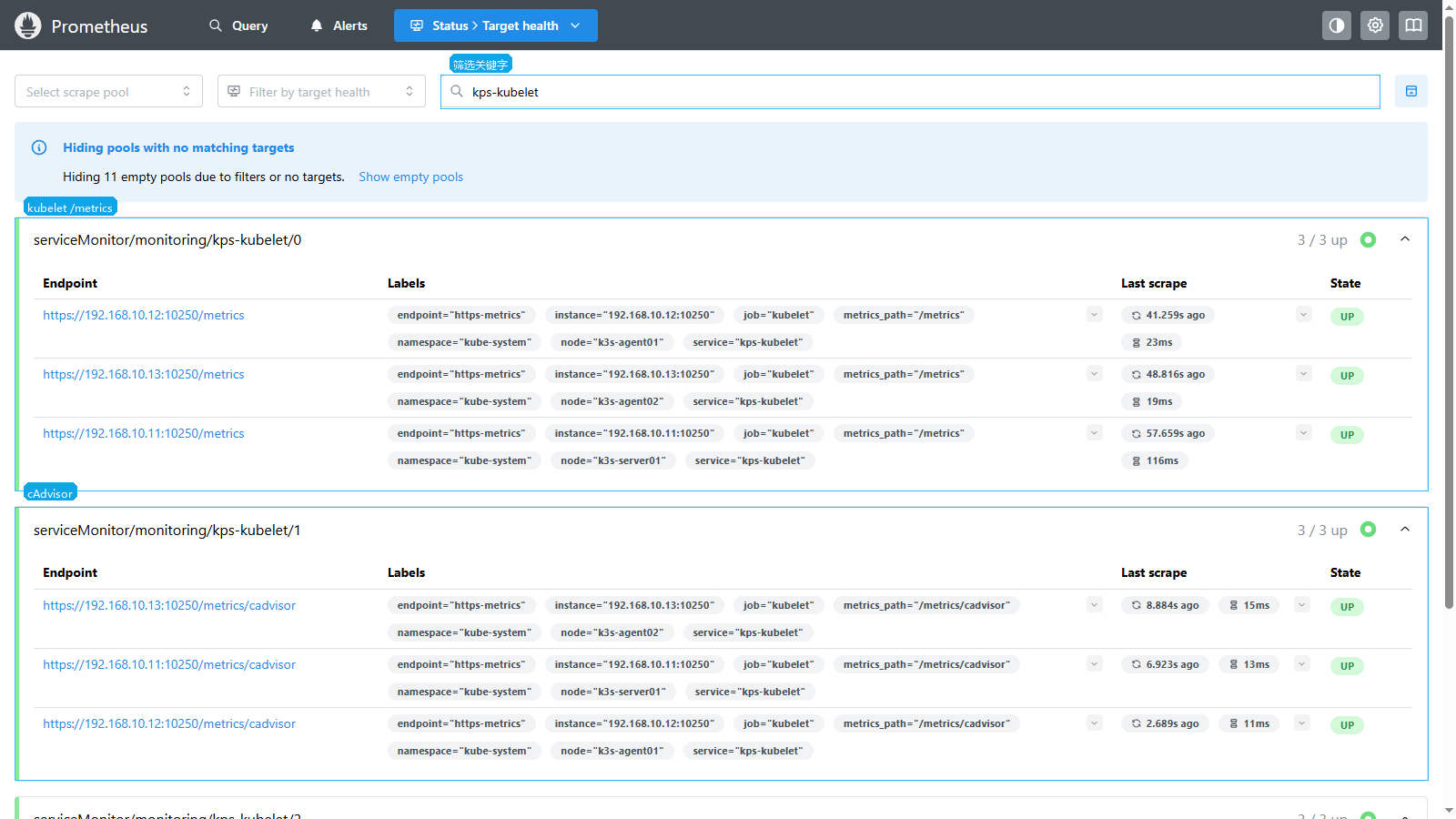
Target DOWN 时,展开对应行看 Last error。kubelet 指标通常走 HTTPS,错误可能来自证书、bearer token、ServiceMonitor 或 kubelet 端口访问。
二、node-exporter
node-exporter 采集主机层指标。K8s 里它通常以 DaemonSet 运行,每台节点一个 Pod。
验证节点数量:
promql
count(node_uname_info)当前结果为 3,说明三台节点都有 node-exporter 数据。
常用主机指标:
promql
# CPU 使用率,按 instance 区分节点
1 - avg by (instance) (
rate(node_cpu_seconds_total{mode="idle"}[5m])
)
# 内存可用比例,MemAvailable 比 free 更接近真实可用内存
node_memory_MemAvailable_bytes
/
node_memory_MemTotal_bytes
# 根分区可用比例,排除 tmpfs 和 overlay
node_filesystem_avail_bytes{mountpoint="/", fstype!~"tmpfs|overlay"}
/
node_filesystem_size_bytes{mountpoint="/", fstype!~"tmpfs|overlay"}
# 网络接收速率,排除 lo 回环网卡
rate(node_network_receive_bytes_total{device!~"lo"}[5m])K3s 节点磁盘要关注这些目录:
| 路径 | 内容 |
|---|---|
/var/lib/rancher/k3s | K3s 数据、镜像、数据库或运行时数据 |
/var/lib/kubelet | kubelet 管理的 Pod、volume 信息 |
/var/lib/rancher/k3s/agent/containerd | containerd 镜像和容器层 |
| local-path PV 目录 | K3s local-path provisioner 创建的本地卷 |
磁盘空间不足时,Node 可能出现 DiskPressure=True,Pod 可能被驱逐,镜像拉取和容器创建也会失败。
三、kubelet 和 cAdvisor
kubelet 是每台节点上的 Kubernetes 代理,负责拉起 Pod、执行探针、上报节点状态、管理容器生命周期。cAdvisor 指标由 kubelet 暴露,提供容器级 CPU、内存、网络和文件系统数据。
kubelet 常见 metrics path:
| metrics path | 说明 |
|---|---|
/metrics | kubelet 自身指标 |
/metrics/cadvisor | 容器资源指标 |
/metrics/probes | 探针执行指标 |
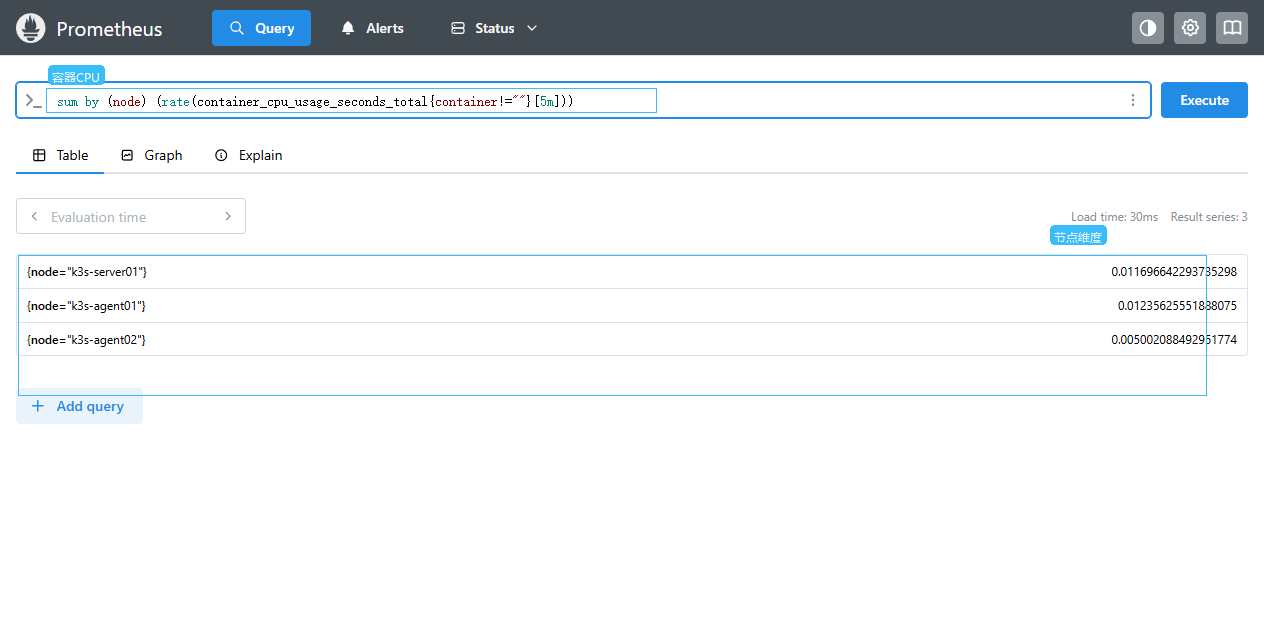
容器 CPU 查询:
promql
sum by (node) (
rate(container_cpu_usage_seconds_total{container!=""}[5m])
)
常用容器资源查询:
promql
# Pod CPU 使用量,适合定位哪个 Pod 消耗 CPU
sum by (namespace, pod) (
rate(container_cpu_usage_seconds_total{container!="", image!=""}[5m])
)
# Pod 内存工作集,接近实际活跃内存
sum by (namespace, pod) (
container_memory_working_set_bytes{container!="", image!=""}
)
# Pod 网络接收
sum by (namespace, pod) (
rate(container_network_receive_bytes_total[5m])
)
# Pod 网络发送
sum by (namespace, pod) (
rate(container_network_transmit_bytes_total[5m])
)CPU 和内存要和 requests/limits 一起看。实际使用量高说明正在消耗资源;requests/limits 接近节点容量,说明调度和限制层面已经紧张。
四、Grafana 节点视图
Grafana 的节点视图适合从结果上看三件事:节点是否健康、资源请求是否集中、CPU/内存曲线是否异常。
节点健康和资源请求:
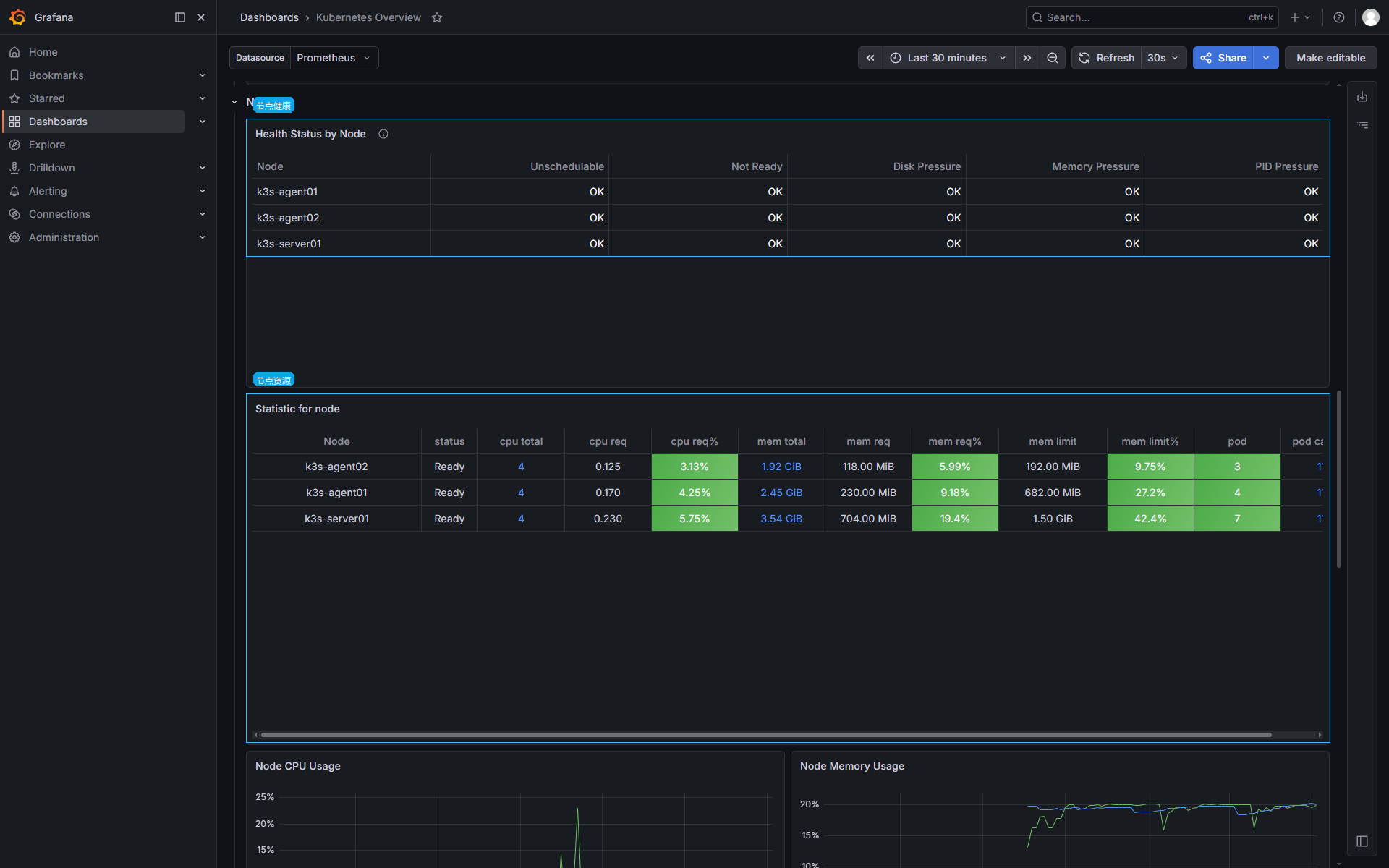
节点 CPU 和内存趋势:
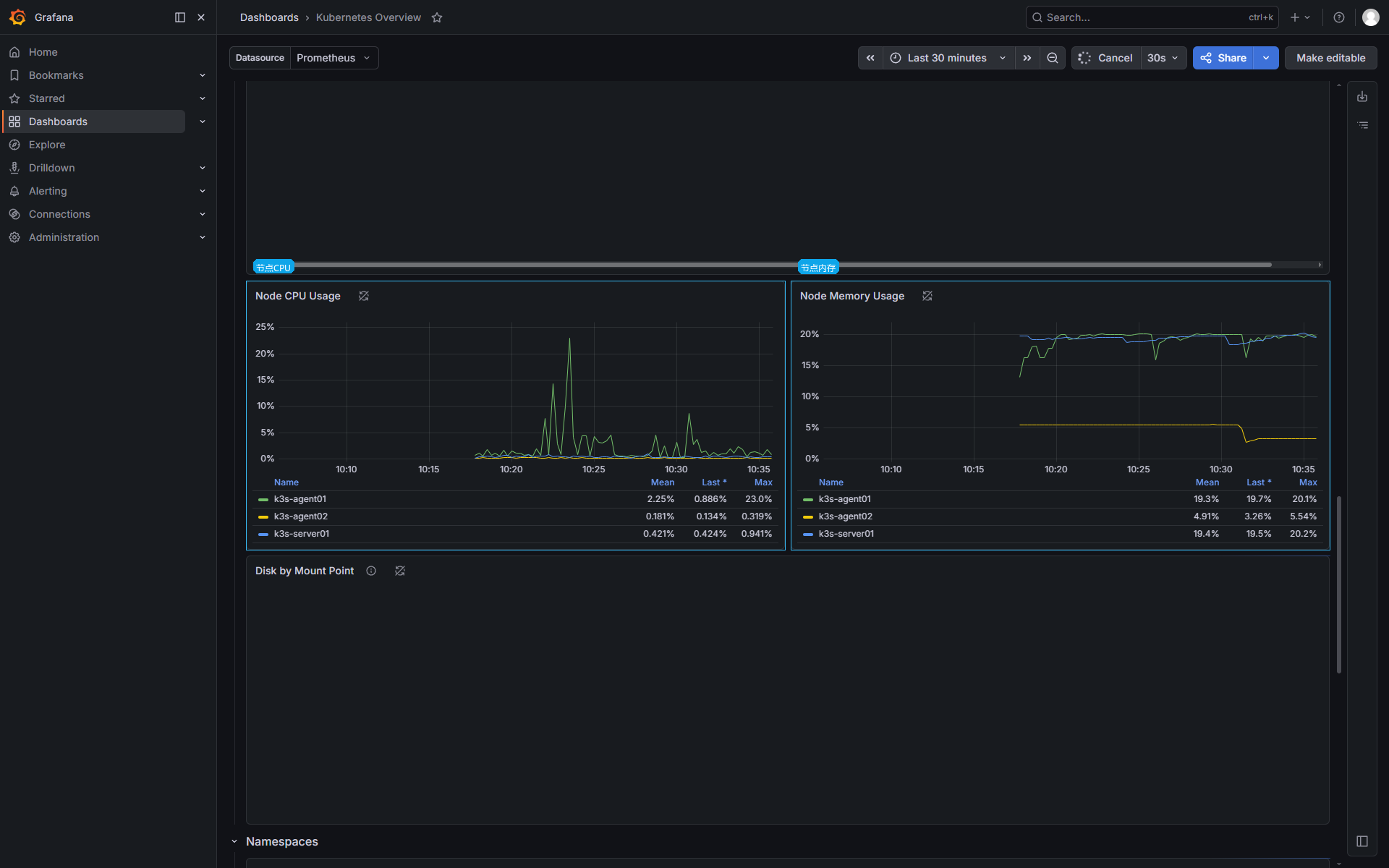
Grafana 面板只是入口。看到某个节点 CPU 或内存异常后,还要回到 Prometheus 或 kubectl top pod 找具体 Pod。
五、当前资源状态
当前三台节点的资源使用:
| 节点 | CPU | 内存 |
|---|---|---|
k3s-agent01 | 50m / 1% | 1263Mi / 50% |
k3s-agent02 | 41m / 1% | 998Mi / 50% |
k3s-server01 | 103m / 2% | 1573Mi / 43% |
监控组件分布:
| Pod | 节点 | 内存 |
|---|---|---|
prometheus-kps-prometheus-0 | k3s-server01 | 约 326Mi |
kps-grafana | k3s-agent01 | 约 263Mi |
alertmanager-kps-alertmanager-0 | k3s-server01 | 约 54Mi,含 config-reloader |
kps-kube-state-metrics | k3s-server01 | 约 68Mi |
kps-operator | k3s-server01 | 约 70Mi |
node-exporter | 三台节点 | 每节点约 27-29Mi |
这组资源说明轻量 values 生效。Grafana 默认 dashboard sidecar、更多规则和长保留时间都会增加内存占用,小内存测试机上很容易把节点压满。
六、节点异常排查
节点异常时,先确认 Node Condition,再看节点上有哪些 Pod,最后回到指标看趋势。
bash
# 查看节点状态、版本和节点 IP
kubectl get nodes -o wide
# 查看 Node Condition、污点、事件和资源分配
kubectl describe node k3s-agent01
# 查看某台节点上运行的 Pod
kubectl get pod -A -o wide \
--field-selector spec.nodeName=k3s-agent01
# 查看节点资源使用
kubectl top node
# 查看内存最高的 Pod
kubectl top pod -A --sort-by=memoryPromQL 侧的常用入口:
promql
# Node condition
kube_node_status_condition
# 最近 15 分钟容器重启
increase(kube_pod_container_status_restarts_total[15m])
# Pod waiting reason
kube_pod_container_status_waiting_reason
# 节点文件系统可用比例
node_filesystem_avail_bytes{mountpoint="/", fstype!~"tmpfs|overlay"}
/
node_filesystem_size_bytes{mountpoint="/", fstype!~"tmpfs|overlay"}常见现象和入口:
| 现象 | 入口 |
|---|---|
NotReady | kubectl describe node、kubelet 日志、节点网络 |
DiskPressure | node-exporter 文件系统指标、镜像目录、日志目录、local-path PV |
MemoryPressure | 节点内存曲线、Pod 内存、OOM 事件 |
| Pod 大量重启 | increase(kube_pod_container_status_restarts_total[15m])、容器日志 |
| Pod 长期 Pending | Events、节点资源、污点、节点选择器、PVC |
节点问题很少只靠一条 CPU 曲线定位。Node Condition、kubelet target、cAdvisor 容器指标、Events 和日志要一起看。