Appearance
K8s监控看板
K8s 看板用于把 Prometheus 里的指标按排查路径固定下来。Prometheus 负责采集和查询,Grafana 负责把常用查询组织成稳定视图。K8s 场景里常见的下钻顺序是集群、节点、namespace、workload、pod、container,再结合告警和事件判断影响范围。
当前看板基于 K3s 集群和 kube-prometheus-stack,K3s 部署参考 K3s 安装部署,监控栈部署参考 K3s部署监控栈。
一、数据源
Grafana 查询 Prometheus 时,不是直接访问 NodePort,而是通过集群内 Service 访问 Prometheus。这样 Grafana Pod 和 Prometheus Pod 都在集群里,访问链路更短,也不受外部端口变化影响。
当前 Grafana 入口:
| 项目 | 值 |
|---|---|
| 地址 | http://192.168.10.11:30300 |
| 用户 | admin |
| 密码 | admin123 |
操作路径:
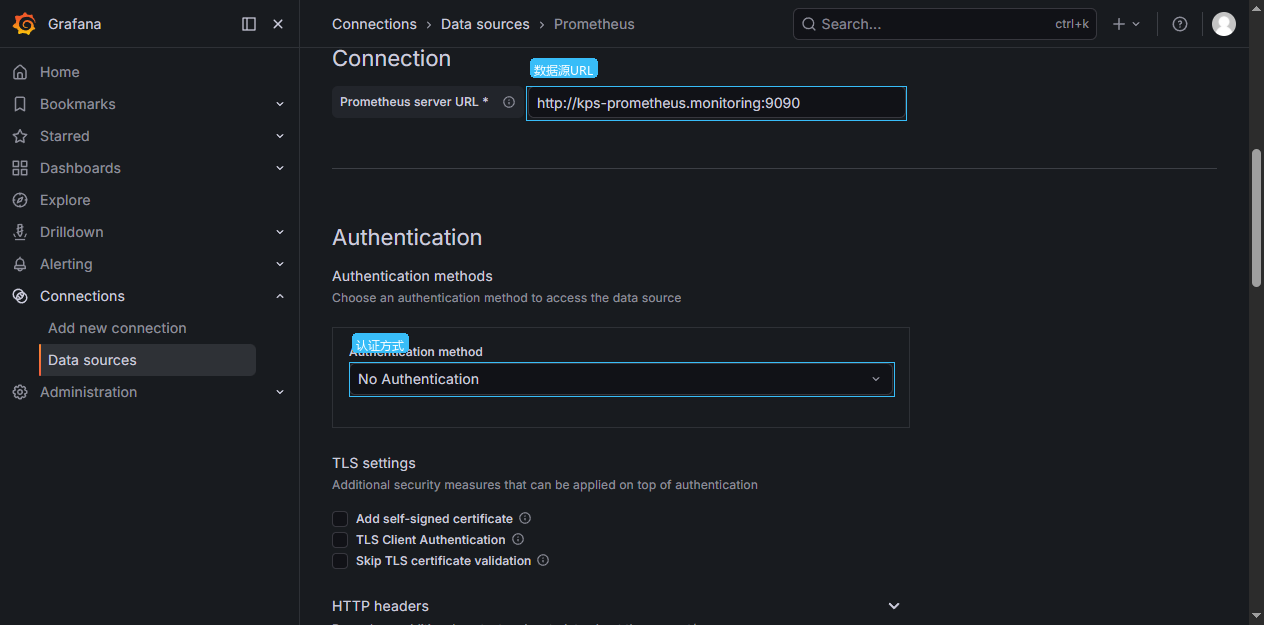
Connections -> Data sources -> Prometheus (中文:连接 -> 数据源 -> Prometheus)
字段填写:
| 字段 | 填写值 | 说明 |
|---|---|---|
Name | Prometheus | 后续 Dashboard 模板选择的数据源名称 |
Prometheus server URL | http://kps-prometheus.monitoring:9090 | Grafana Pod 通过集群 DNS 访问 Prometheus Service |
Authentication methods | No Authentication | 当前 Prometheus 没有额外认证 |
保存后验证:
Connections -> Data sources -> Prometheus -> Save & test (中文:连接 -> 数据源 -> Prometheus -> 保存并测试)
出现 Successfully queried the Prometheus API,说明 Grafana 可以查询 Prometheus。
命令行也可以验证数据源健康状态:
bash
curl -sS -u admin:admin123 \
http://127.0.0.1:30300/api/datasources/uid/prometheus/health返回里有 Successfully queried the Prometheus API,数据源链路就是通的。
二、导入现成模板
K8s 看板不适合从零随手拼几个面板。现成模板能覆盖一批常见维度,比如节点健康、资源请求、Pod 状态、namespace 分布和 Deployment 副本状态。导入后再根据环境修变量和查询,比直接做一张空白 Dashboard 更容易形成可用视图。
操作路径:
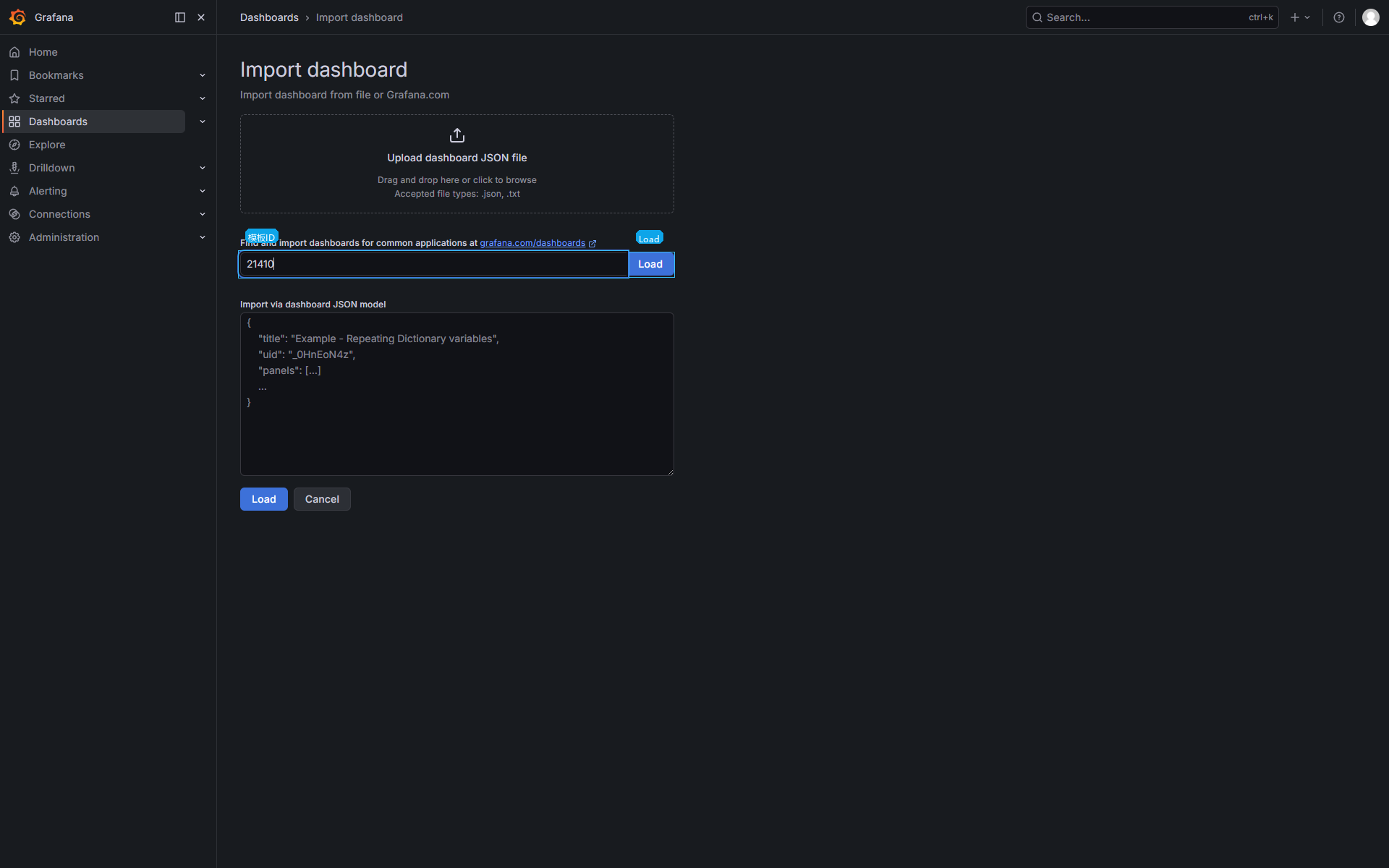
Dashboards -> New -> Import (中文:仪表盘 -> 新建 -> 导入)
操作步骤:
- 进入
Dashboards -> New -> Import。 - 在
Find and import dashboards for common applications at grafana.com/dashboards输入模板 ID。 - 点击
Load。 - 在导入确认页选择数据源
Prometheus。 - 点击
Import保存。
字段填写:
| 字段 | 填写值 | 说明 |
|---|---|---|
| Dashboard ID | 21410 | Kubernetes / Overview,当前主看板 |
| Datasource | Prometheus | 对应上面配置的数据源 |
| Folder | 默认或自定义目录 | 小环境里默认目录即可 |
本次保留的模板:
| ID | 名称 | 用途 |
|---|---|---|
21410 | Kubernetes / Overview | 主看板,覆盖全局资源、对象数量、节点、namespace |
14518 | Kubernetes Cluster Overall Dashboard | 补充节点列表和 namespace 网络流量 |
13332 | kube-state-metrics-v2 | 补充 kube-state-metrics 对象状态,尤其是 Deployment 副本 |
导入完成后,Dashboard 右上角时间范围先用 Last 30 minutes,刷新间隔可以设为 30s。刚部署完的集群历史数据少,时间范围太大时图上会有一段空白。
三、全局资源视图
全局视图先看 CPU、内存和对象数量。这里不是为了判断某台机器的 Linux 负载,而是先确认集群资源池是否足够、requests 和 limits 是否明显偏离实际使用。
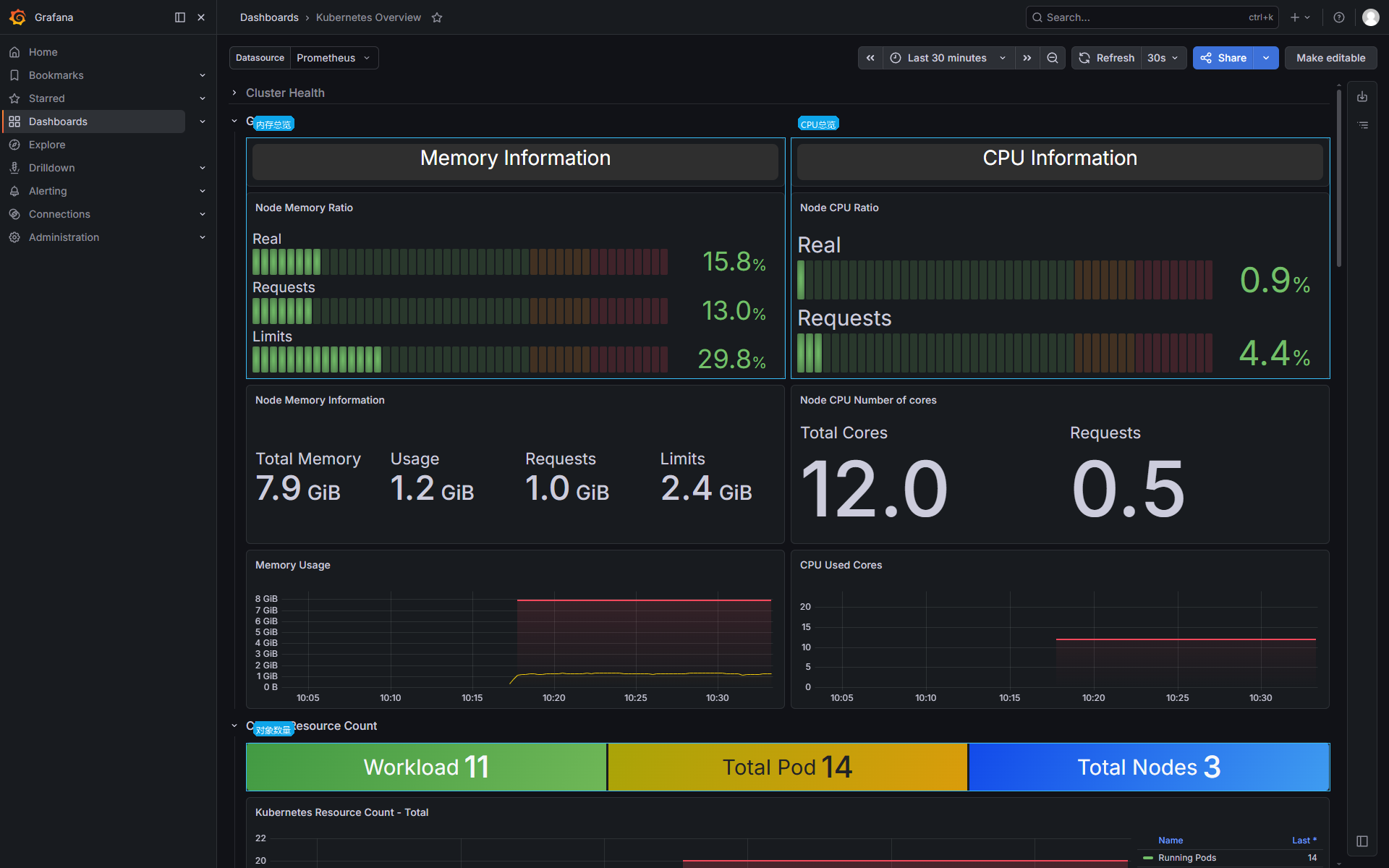
几个指标的含义:
| 面板 | 看法 |
|---|---|
Real | 当前真实使用量,来自实际采集到的资源消耗 |
Requests | Pod 声明的资源请求,调度器主要按它判断能不能放下 |
Limits | Pod 资源上限,CPU 会被限制,内存超过后可能 OOM |
Workload / Total Pod / Total Nodes | 对象规模,用来判断当前集群大概跑了多少东西 |
资源请求长期接近总量时,扩容或发布新 Pod 会更容易 Pending。真实使用很低但 requests 很高,常见原因是资源声明偏保守;真实使用接近 limits,容器可能出现 CPU throttling 或 OOM。
资源对象数量和 Pod QoS 可以放在同一屏里看:
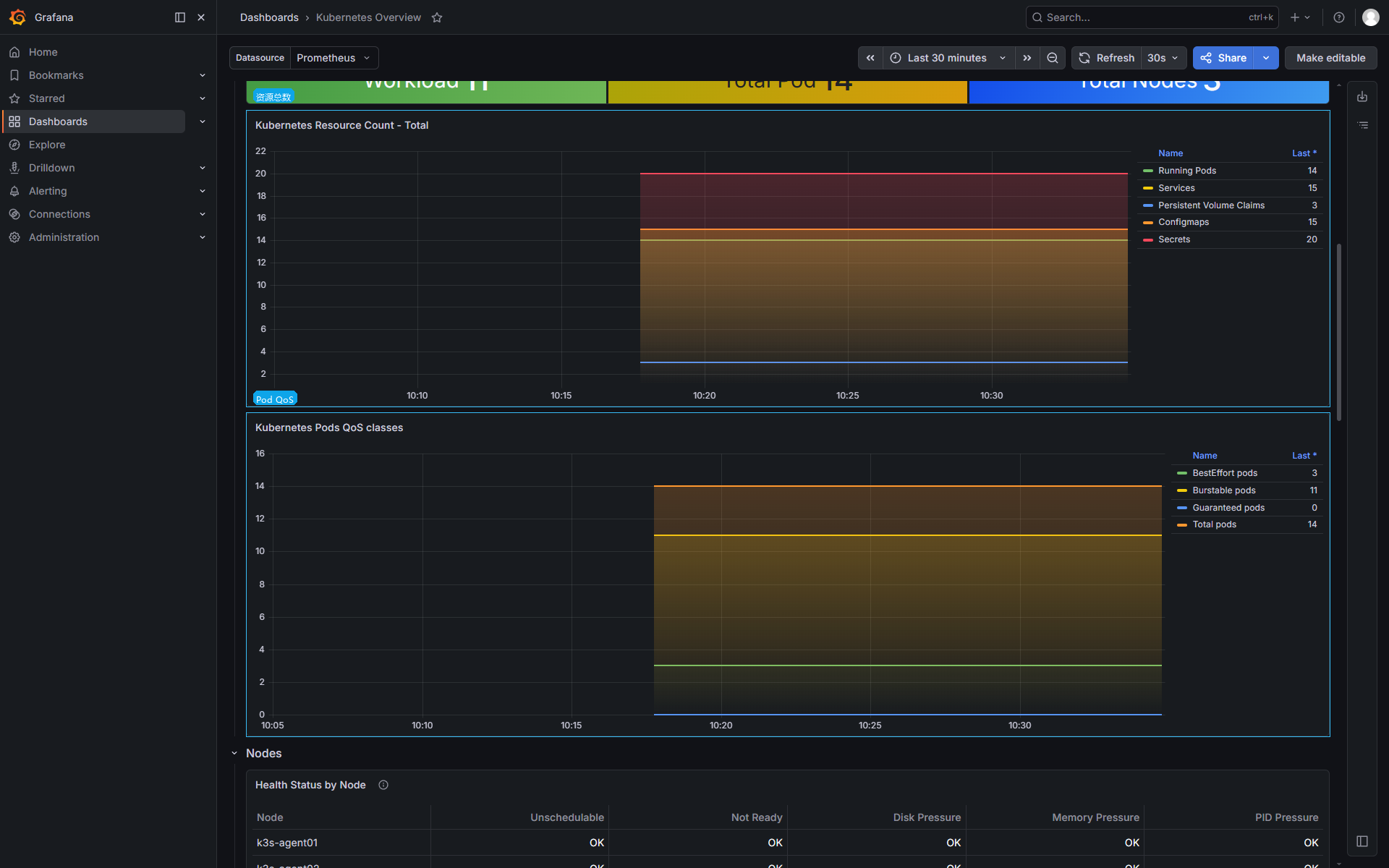
QoS 这里反映 Pod 的资源声明情况:
| QoS | 常见情况 |
|---|---|
Guaranteed | CPU 和内存的 requests、limits 都设置且相等 |
Burstable | 设置了部分 requests 或 limits |
BestEffort | 没有设置 requests 和 limits |
节点资源紧张时,BestEffort Pod 更容易被驱逐。业务 Pod 大量处于 BestEffort,通常说明资源声明没有整理好。
四、节点视图
节点视图先看 Ready、DiskPressure、MemoryPressure、PIDPressure 这类状态。它们来自 kube-state-metrics,反映 Kubernetes API 里的 Node Condition。
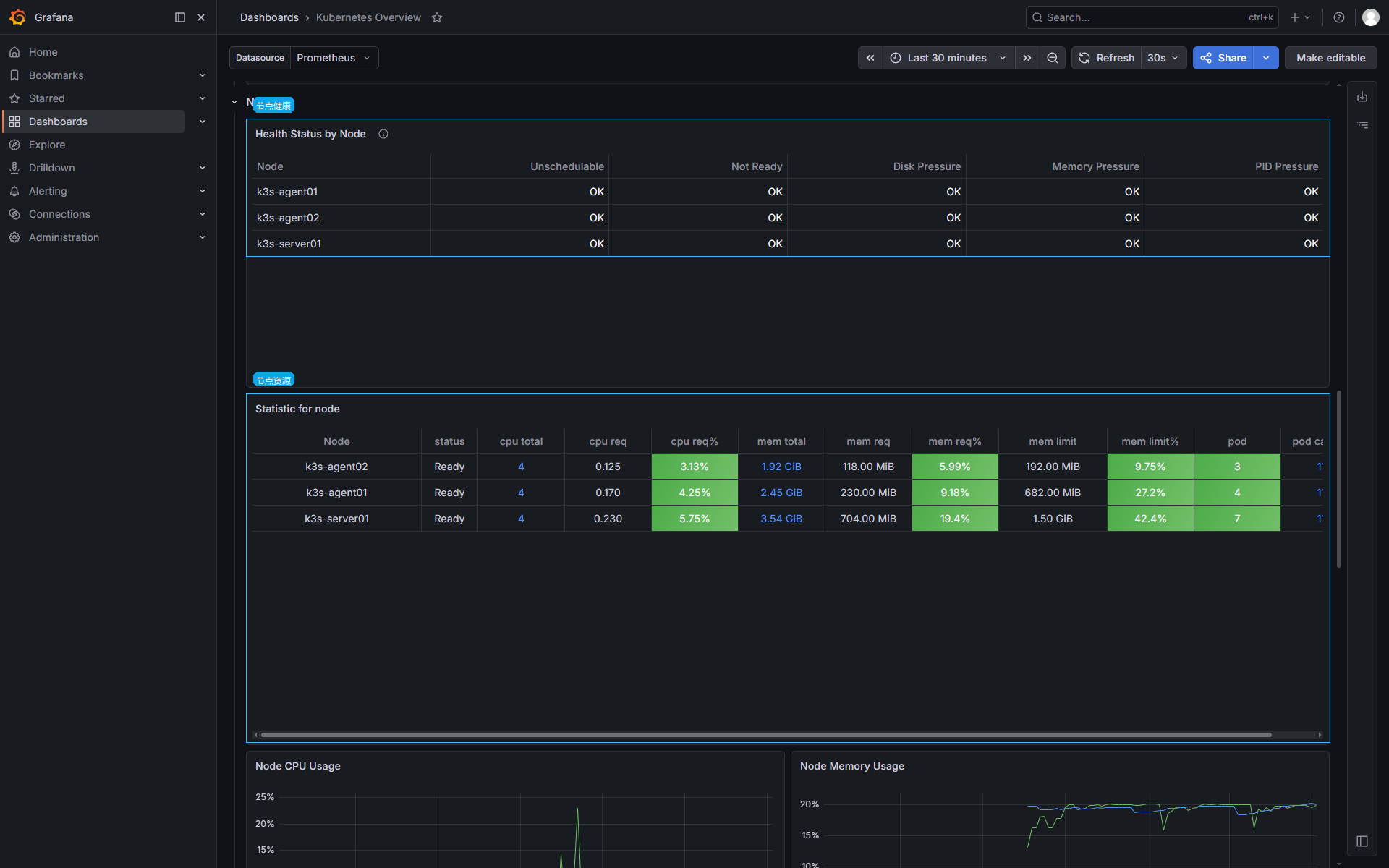
节点表格里常看这些列:
| 列 | 含义 |
|---|---|
status | 节点是否 Ready |
cpu req% | 当前节点上 Pod requests 占节点 CPU 的比例 |
mem req% | 当前节点上 Pod requests 占节点内存的比例 |
mem limit% | 当前节点上 Pod limits 占节点内存的比例 |
pod | 当前节点承载的 Pod 数量 |
节点状态表里全是 OK,只说明 Node Condition 没有异常。实际 CPU、内存曲线还要继续看。
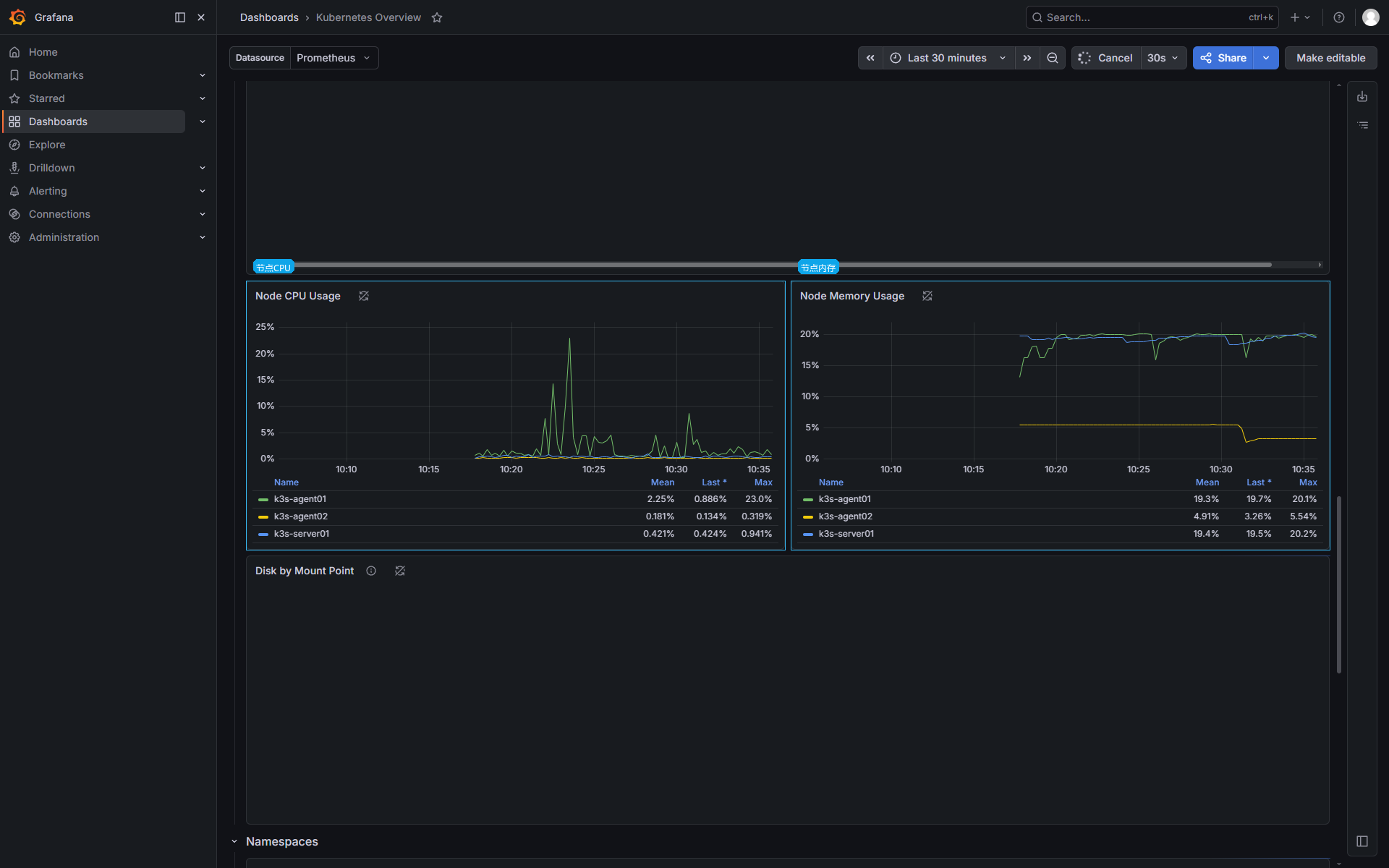
节点 CPU 有尖峰时,先看是否某个 Pod 突然消耗 CPU,再看 kubelet、containerd、日志采集和监控组件本身。节点内存接近高位时,结合 kubectl top pod -A --sort-by=memory 和 Dashboard 里的 namespace 维度继续下钻。
五、namespace 和工作负载
namespace 视图用于判断异常集中在哪个业务空间。比如 Pod Pending、Failed、Unknown、Unschedulable 出现在某个 namespace 时,后续排查就从这个 namespace 下的 Deployment、Pod、Events 进入。
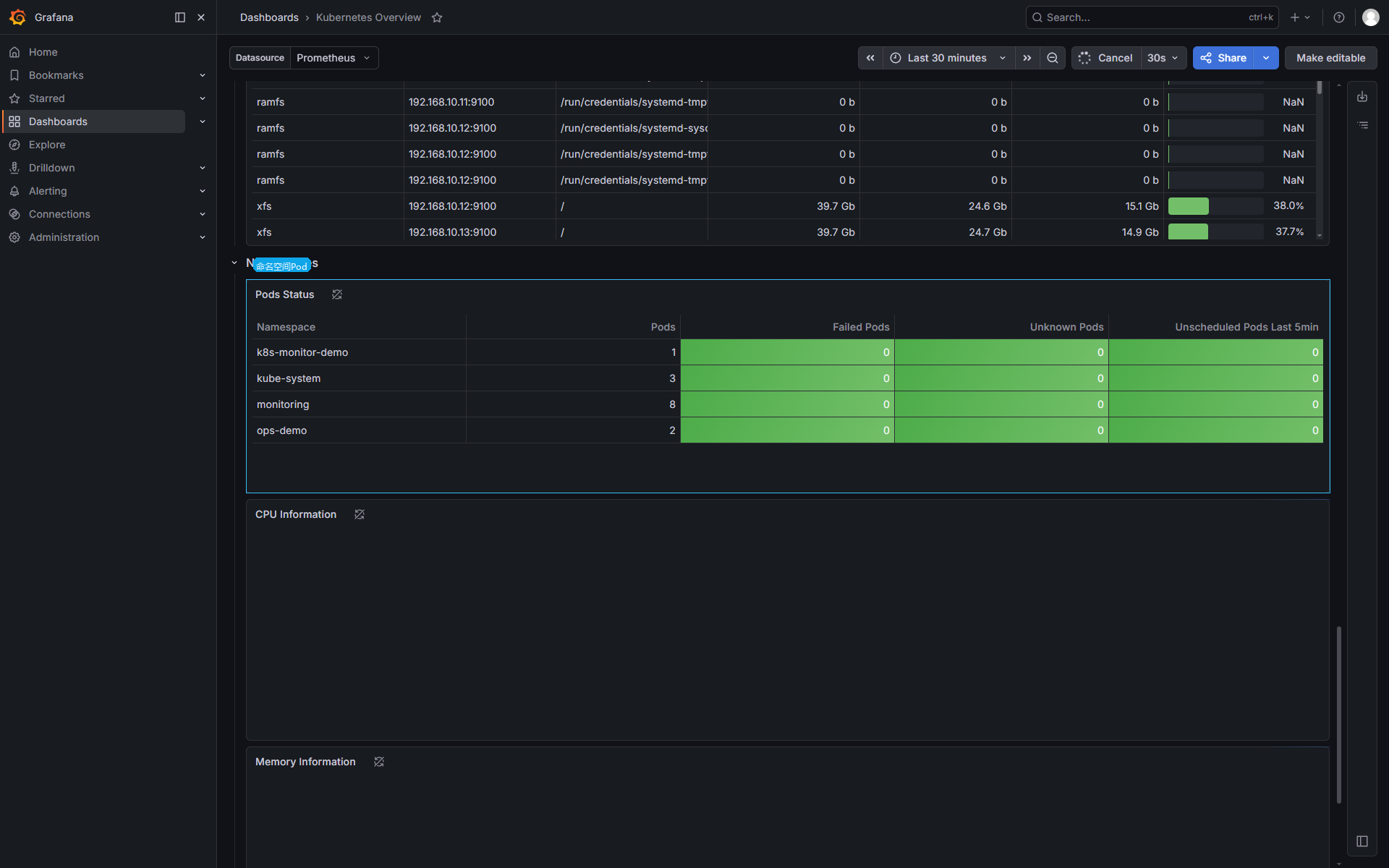
namespace 表格的几列:
| 列 | 含义 |
|---|---|
Pods | 当前 namespace 下 Pod 数量 |
Failed Pods | 失败状态 Pod 数量 |
Unknown Pods | 状态未知的 Pod 数量 |
Unscheduled Pods Last 5min | 最近 5 分钟不可调度的 Pod 数量 |
Unscheduled Pods Last 5min 有值时,常见原因是资源不足、节点选择器不匹配、污点容忍不匹配、PVC 没有绑定。对应命令入口:
bash
# 查看 Pending Pod 分布
kubectl get pod -A --field-selector=status.phase=Pending -o wide
# Events 里通常会写出调度失败原因
kubectl describe pod -n <namespace> <pod-name>Deployment 副本状态适合用 kube-state-metrics 模板补充查看。它比“Pod Running 数量”更贴近发布状态,因为 Deployment 关心期望副本、更新副本、可用副本和不可用副本。
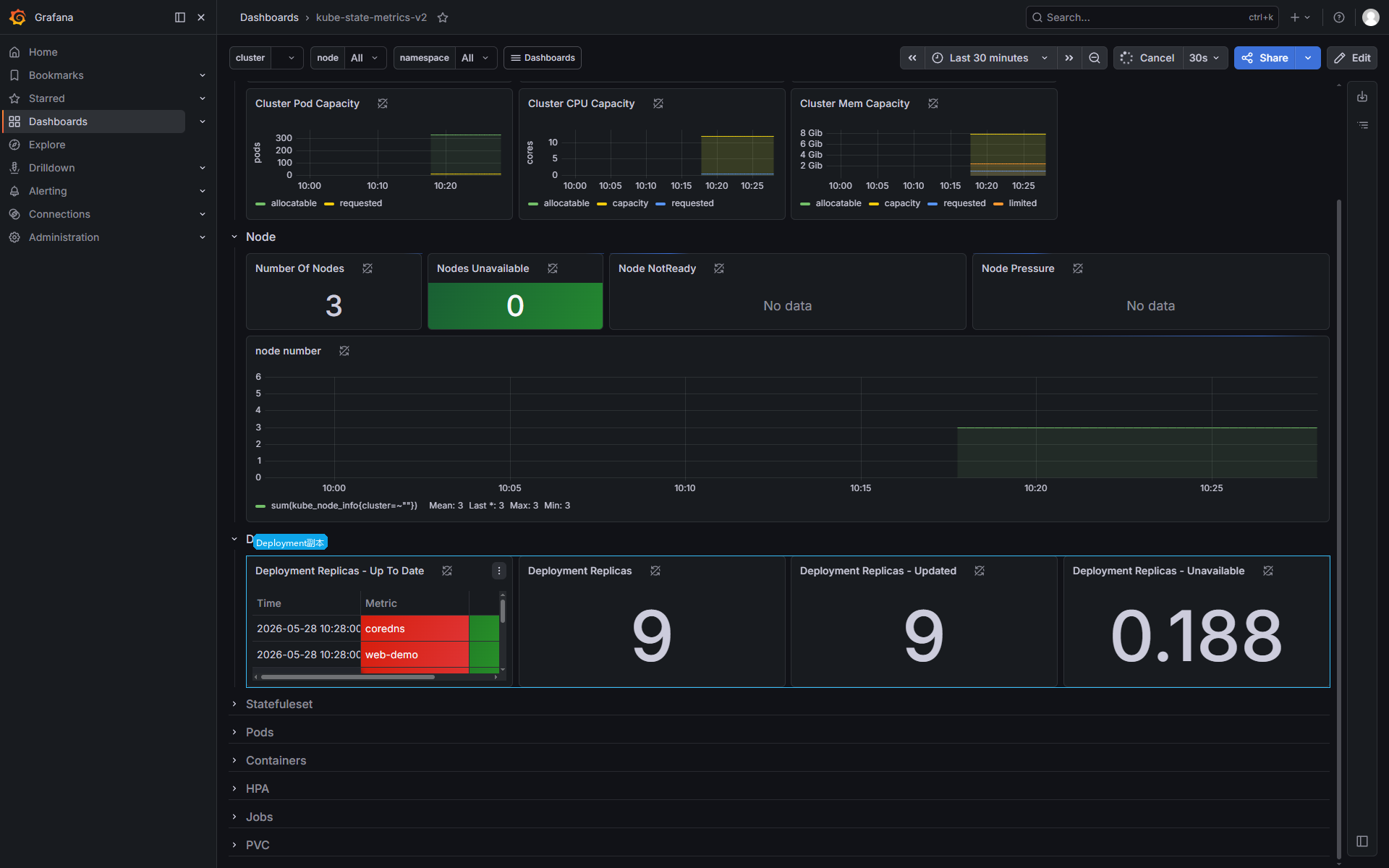
Deployment 不可用副本大于 0 时,常见入口:
bash
# 查看 Deployment 当前状态
kubectl -n <namespace> get deploy <deployment-name> -o wide
# 查看副本集和 Pod 是否创建成功
kubectl -n <namespace> get rs,pod -l app=<app-label> -o wide
# Events 里能看到镜像拉取、探针失败、调度失败等原因
kubectl -n <namespace> describe deploy <deployment-name>六、PromQL 和看板对应关系
看板上的每个面板最终都来自 PromQL。看板异常时,把面板里的查询拿到 Prometheus Query 页面执行,可以更快判断是数据源问题、模板变量问题,还是指标本身没有采到。
常用对应关系:
| 看板问题 | PromQL 入口 |
|---|---|
| 节点数量 | count(kube_node_info) |
| 节点 Ready | kube_node_status_condition{condition="Ready"} |
| Pod 数量 | count(kube_pod_info) |
| namespace Pod 分布 | count by (namespace) (kube_pod_info) |
| Pod 重启 | increase(kube_pod_container_status_restarts_total[30m]) |
| Deployment 不可用副本 | kube_deployment_status_replicas_unavailable |
| CPU 使用率 | rate(container_cpu_usage_seconds_total{container!=""}[5m]) |
| 内存使用量 | container_memory_working_set_bytes{container!=""} |
Prometheus Query 适合调试看板里的 PromQL。比如 namespace 维度的 Pod 分布,可以直接查 kube-state-metrics 指标:
操作路径:
Query -> Table (中文:查询 -> 表格)
查询 Pod 对象分布:
promql
sum by (namespace, pod) (
kube_pod_info
)
七、排错入口
| 现象 | 检查入口 | 常见原因 |
|---|---|---|
| Dashboard 全部无数据 | Connections -> Data sources -> Prometheus -> Save & test | 数据源 URL 错、Prometheus Service 不通、认证配置不一致 |
| 只有部分面板无数据 | 面板编辑页查看 PromQL 和变量 | 模板依赖的指标当前没有采到,或变量没有选中 |
| 下拉变量为空 | Dashboard 顶部变量、Prometheus 查询 label_values 对应指标 | 变量查询依赖的指标不存在,或数据源 UID 映射错 |
| 图上只有一小段数据 | 右上角时间范围 | 刚部署完历史数据少,时间范围比采集时长大 |
| namespace 或 pod 维度丢失 | 面板 PromQL 的 sum by (...) | 聚合时把 namespace、pod、container 标签聚掉了 |
| 面板显示数据但排查不够 | 回到 Prometheus Query 执行原始 PromQL | 看板只适合固定视图,临时排查还要直接查 PromQL |
Dashboard 是排查入口,不是结论本身。真正定位时还要把看板里的异常维度带回到 kubectl describe、Events、Pod 日志和 Prometheus 原始查询里。